
- Today
- Total
DATA101
[파이썬/NLP] 빠르게 한국어 형태소 분석하는 방법 (feat. KoNLPy) 본문
📚 목차
1. KoNLPy setup
1.1. KoNLPy 설치
1.2. KoNLPy import
1.3. 형태소 분석기 비교
2. 형태소별 토큰화(tokenization)하기
2.1. 토큰화 without 품사 태깅
2.2. 토큰화 with 품사 태깅
2.3. 명사만 추출하기
1. KoNLPy setup
1.1. KoNLPy 설치
KoNLPy 라이브러리가 설치되어 있지 않는 분들은 아래 링크를 참고하셔서 설치해 주시길 바랍니다.
heytech.tistory.com/3
[Python/NLP] MacOS에서 KoNLPy 설치하기
오늘은 한국어 자연어처리(NLP)를 위한 파이썬 라이브러리 KoNLPy를 MacOS에서 설치하는 방법을 공유합니다. 1. 사전 설치항목 1.1. MacOS/Linux 패키지 매니저 https://brew.sh/index_ko Homebrew The Missing P..
heytech.tistory.com
1.2. KoNLPy import
from konlpy.tag import Mecab
mecab = Mecab()KonNLPy 설치가 완료되었다면 이제 파이썬에서 KoNLPy 라이브러리를 import 합니다. 이번 포스팅에서는 KoNLPy에서 제가 주로 사용은 Mecab 형태소 분석기를 사용하겠습니다. 만약 Mecab 형태소 분석기가 정상적으로 동작하지 않는다면, 아래 포스팅을 참고해 주세요!
https://heytech.tistory.com/395
Mecab 설치 에러 해결하기: Exception: Install MeCab in order to use it: http://konlpy.org/en/latest/install/
👨💻 들어가며 KoNLPy와 Mecab 패키지는 기본적으로 설치되어 있다고 가정합니다. 혹시나 설치되어 있지 않다면 아래 포스팅을 참고해 주세요. https://heytech.tistory.com/3 [Python/NLP] KoNLPy 설치하는
heytech.tistory.com
1.3 형태소 분석기 비교
형태소 분석기는 어떤 것이 가장 좋을까? KoNLPy 라이브러리는 Kkma, Okt, Mecab, Komoran 등 여러 한국어 형태소 분석기를 지원합니다. 그중에서도 저는 주로 빠른 연산속도뿐만 아니라 우수한 토큰화 품질을 갖춘 Mecab 형태소 분석기를 애용합니다. 하지만 모든 상황에서 Mecab 분석기가 단연 좋은 것도 아닙니다. 이와 관련하여 다른 블로거의 형태소 분석기 성능 비교 게시글 링크를 공유해 드립니다. 이를 참고하시어 분석 목적에 맞게 형태소 분석기를 선택하시길 바랍니다.
iostream.tistory.com/144#header-n14
한국어 형태소 분석기 성능 비교
korean-tokenizer-experiments 형태소 분석기 비교실험 환경하드웨어 (MacBook Pro Mid 2015)소프트웨어데이터실험 내용실행 시간 비교로딩 시간형태소 분석 시간문장 분석 품질 비교띄어쓰기가 없는 문장자
iostream.tistory.com
2. 형태소별 토큰화(tokenization)하기
Mecab 형태소 분석기의 사용방법을 예시로 소개해 드립니다.
2.1. 토큰화 without 품사 태깅
# To tokenize text data based on morphemes without the tagging
mecab.morphs("안녕하세요, 헤이 테크 블로그의 자연어처리 관련 포스팅입니다. 1234-!5123 @!@!@@$")토큰화 결과(그림 1)

Mecab 형태소 분석기 내 morphs 함수를 통해 별도의 형태소 태깅 없이 예시 문장을 형태소별로 토큰화 한 결과입니다. 한글과 구두점, 특수문자 간에도 토큰화를 정상적으로 지원하는 것을 알 수 있습니다. 또한, mecab morphs 함수는 string 문자열을 입력받아 1차원 list 형태로 return 합니다.
2.2. 토큰화 with 품사 태깅
# To tokenize text data based on morphemes wit the tagging
mecab.pos("안녕하세요, 헤이 테크 블로그의 자연어처리 관련 포스팅입니다. 1234-!5123 @!@!@@$")토큰화 결과(그림 2)
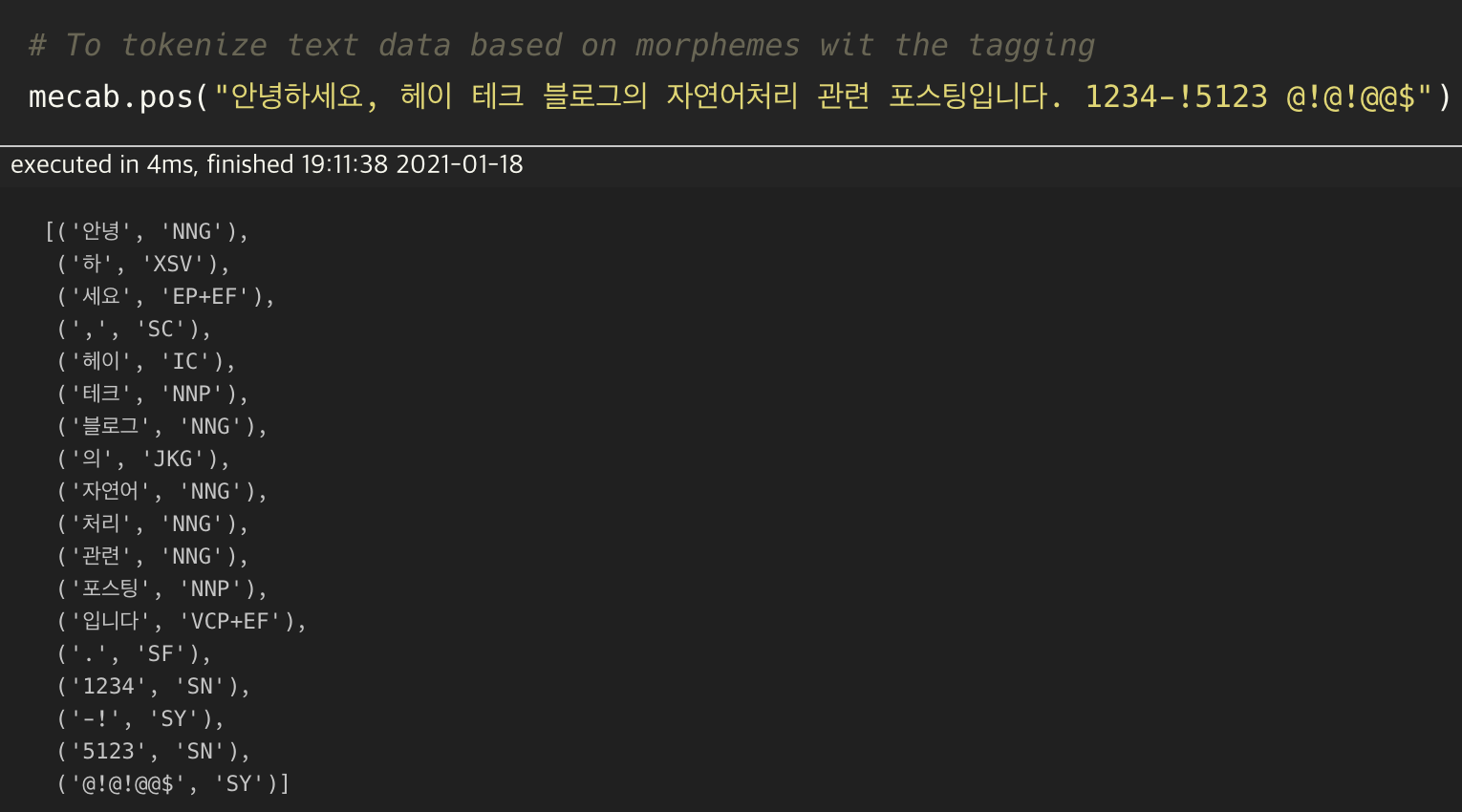
이번에는 Mecab 내 pos 함수를 통해 예시 문장을 품사 태깅과 함께 토큰화 하였습니다. 결과 스크린샷에서 보실 수 있듯이, string을 입력받아 리스트 안에 튜플 형태로 데이터를 반환해 줍니다. 태깅에 대한 품사 정보는 아래에 잘 정리되어 있으니 참고하시길 바랍니다.
docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0
Korean POS tags comparison chart
chart Not provided in KoNLPy,Provided in KoNLPy Sejong project (ntags=42),Sim Gwangsub project (ntags=26),Twitter Korean Text (ntags=19),Komoran (ntags=42),Mecab-ko (ntags=43),Kkma (ntags=10),Kkma (ntags=30),Kkma (ntags=56),Hannanum (ntags=9),Hannanum (nta
docs.google.com
2.3. 명사만 추출하기
# To extract only noun in text data
mecab.nouns("안녕하세요, 헤이 테크 블로그의 자연어처리 관련 포스팅입니다. 1234-!5123 @!@!@@$")토큰화 결과(그림 3)

📚 참고할 만한 포스팅
Mecab 설치 에러 해결하기: Exception: Install MeCab in order to use it: http://konlpy.org/en/latest/install/
👨💻 들어가며 KoNLPy와 Mecab 패키지는 기본적으로 설치되어 있다고 가정합니다. 혹시나 설치되어 있지 않다면 아래 포스팅을 참고해 주세요. https://heytech.tistory.com/3 [Python/NLP] KoNLPy 설치하는
heytech.tistory.com
👨💻 맞춤 서비스
저희 AI/BigData 분석 솔루션 전문 브랜드 <데이터워너원 DATA101>에서는
맞춤형 데이터 수집부터 통계분석, 텍스트마이닝, AI 모델링, 논문작성을 지원해 드립니다 :)
자세한 내용은 아래 링크를 참고해 주세요!
데이터분석, 통계분석, 논문작성 지원해 드립니다. - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p>Python, SPSS, Tableau를 활용해 <strong>...
kmong.com
텍스트 데이터 분석/텍스트마이닝NLP 도와드립니다. - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p>대기업 AI/빅데이터 연구원 출신으로 구성된 법인 주식회사 유에프5는 Py...
kmong.com
유튜브 댓글 원하는 만큼 수집해 드립니다/웹 크롤링 - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p><strong style="font-size: 24px;&q...
kmong.com
모바일 앱 리뷰 크롤링/구글 플레이 스토어 - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p><strong>구글 플레이 스토어 앱 리뷰 1시간 안에 수집해 ...
kmong.com
포스팅 내용에 오류가 있다면 아래에 댓글 남겨주세요!
그럼 오늘도 즐겁고 건강한 하루 보내시길 바랍니다.
고맙습니다 :)
'AI & 빅데이터 > 자연어처리(NLP)' 카테고리의 다른 글
| [파이썬/NLP] 문자열 치환하기 (찾아바꾸기) (0) | 2021.02.16 |
|---|---|
| [파이썬/NLP] 이모티콘을 텍스트로, 텍스트를 이모티콘으로 변환하기! (0) | 2021.02.01 |
| [NLP] KoNLPy Mecab 고유명사 등록 방법 (1) | 2021.01.24 |
| [Python/NLP] 텍스트 내 이모티콘/이모지 제거하는 방법! (0) | 2021.01.16 |
| [Python/NLP] KoNLPy 설치하는 방법에 대해 알아보자! (0) | 2021.01.10 |



