
DATA101
[NLP] 언어모델의 평가지표 'Perplexity' 개념 및 계산방법 본문
📌 Text 빅데이터분석 플랫폼 베타테스트 참가자 모집 중!(네이버페이 4만 원 전원 지급)

👋 안녕하세요, 코딩이 필요 없는 AI/빅데이터 분석 All in One 플랫폼 <DATA101> 개발팀입니다.
😊 저희 서비스를 사용해 보시고 경험담을 들려주세요 :)
💸 참여해 주신 "모든" 분들께 네이버페이 4만 원 쿠폰을 지급해 드립니다.
👨💻 참여 희망 시 카톡플러스친구 1:1 채팅 or 인스타그램 DM 부탁드립니다 :)
📆 참여기간 : 11/25(월)~11/29(금) 11:00~21:00 중 택1 (1시간 1타임)
👉 참여장소 : 강남역 인근 스터디카페 미팅Room
📍 소요시간 : 총 40분 내외(서비스 체험 및 인터뷰 포함)
✅ 참가조건 : Text 빅데이터 분석 업무 경험자
👉 참가 가능일정 조회하기 : https://url.kr/n8k8gu
- 카톡플친 : http://pf.kakao.com/_SxltHG/chat
- 인스타그램 : https://www.instagram.com/data101.official/
📚 목차
1. Perplexity 개념
2. Perplexity 값의 의미
3. Perplexity 계산방법
1. Perplexity 개념
1.1. 개요
Perplexity(PPL)는 텍스트 생성(Text Generation) 언어 모델의 성능 평가지표 중 하나입니다. Perplexity는 '펄플렉서티'라고 읽으며, '(무언가를 이해할 수 없어) 당혹스러운 정도' 또는 '헷갈리는 정도'로 이해하시면 됩니다(cf., 네이버 영어사전). 일반적으로 테스트 데이터셋이 충분히 신뢰할 만할 때 Perplexity 값이 낮을수록 언어 모델이 우수하다고 평가합니다. 이에 대한 내용은 이어지는 '2. Perplexity 값의 의미' 섹션에서 더욱 자세히 다룹니다.
1.2. 분기계수
Perplexity는 곧 언어 모델의 분기계수(Branching Factor)입니다. 여기서 분기계수란 Tree 자료구조에서 branch의 개수를 의미하고(아래 그림 1 참고), 한 가지 경우를 골라야 하는 Task에서 선택지의 개수를 뜻합니다. 예를 들어, 체스에서 게임 턴마다 말을 움직일 수 있는 경우가 평균적으로 31~35가지이고, 바둑에서는 바둑돌을 둘 수 있는 곳이 평균 250가지로 알려져 있습니다(참고). 즉, 체스와 바둑의 경우 평균 branching factor가 각각 31~35, 250인 것이고, 값이 클수록 경우의 수가 많으니 복잡한 문제라는 것을 뜻합니다.
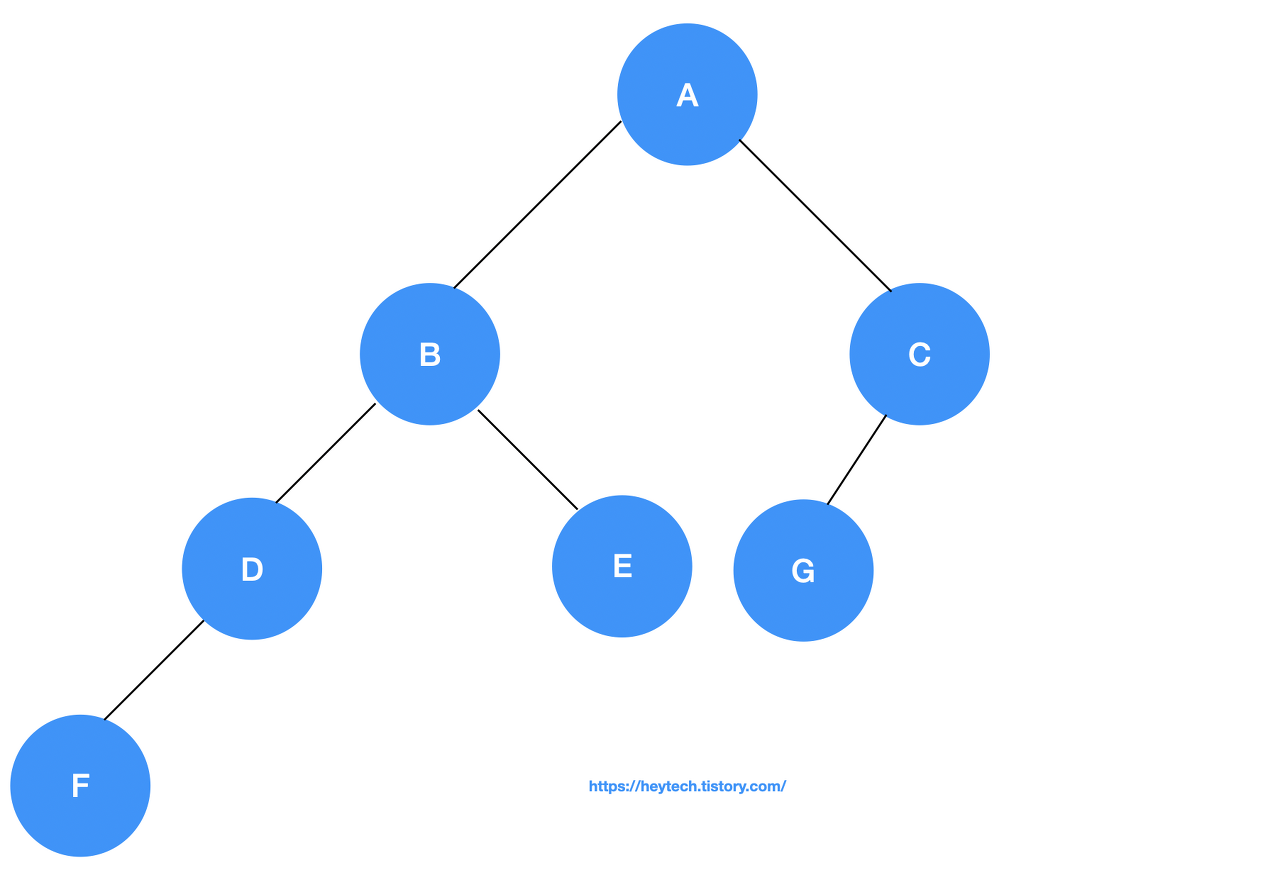
언어 모델에서 Perplexity, 즉 분기계수는 이전 단어로 다음 단어를 예측할 때 몇 개의 단어 후보를 고려하는지를 의미합니다. 여기서 고려해야 할 단어 후보가 많다는 것은 그 만큼 언어 모델이 쉽게 정답을 못 내고 있다고 해석할 수 있습니다. 즉, Perplexity 값이 낮을수록 언어 모델이 쉽게 정답을 찾아내는 것이므로 성능이 우수하다고 평가합니다. 단, 이때 모델 평가에서 활용한 테스트 데이터셋의 신뢰도가 높은 경우에만 이렇게 말할 수 있습니다. 이에 대한 부연 설명은 이어지는 2번째 섹션에서 자세히 다룹니다.
2. Perplexity 값의 의미
일반적으로 Perplexity는 값이 낮을수록 언어 모델의 성능이 우수하다고 평가합니다. 단, 이는 모델 평가 시 활용한 테스트 데이터셋이 충분히 신뢰도가 높을 때만 적용됩니다. 테스트 데이터셋이 신뢰도가 높다는 것은 테스트 데이터가 충분히 많고, 언어 모델을 활용할 도메인에 적합한 테스트 데이터셋으로 구성된 경우를 의미합니다. 즉, 단순히 Perplexity가 낮다는 것은 모델 평가 시 활용한 테스트 데이터에서 해당 언어 모델이 높은 정확도를 보였다는 것을 의미합니다. 따라서 Perplexity 값이 낮을 뿐만 아니라 테스트 데이터셋의 신뢰도가 높아야 사람이 직접 언어 모델이 예측한 문장 또는 단어를 봤을 때 정확도가 높다고 느낄 수 있습니다.
3. Perplexity 계산방법
수학에서 시퀀스(Sequence)는 순서를 고려하여 나열된 여러 객체들의 묵음을 의미한다는 점에서, 문장은 어순을 고려하여 여러 단어로 이루어진 단어 시퀀스(Word Sequence)라고도 부릅니다. 단어의 개수가
문장의 확률에 체인 룰(Chain Rule)을 적용하여 Perplexity(PPL)를 계산하면 아래와 같습니다.
위 수식은 언어 모델이 성능 평가를 위한 테스트 데이터셋에서 이전 단어들을 기반으로 다음 단어를 예측할 때마다 평균적으로
📚 참고할 만한 포스팅
1. [NLP] Bag of Words(BoW) 개념 및 실습
2. [NLP] 문서 단어 행렬(DTM) 개념 이해
3. [NLP] TF-IDF 개념 및 계산 방법
4. [NLP] Word Embedding의 이해: (1) 희소표현 및 밀집표현
5. [NLP] 언어모델(Language Model)의 개념 및 특징
6. [NLP] N-gram 언어 모델의 개념, 종류, 한계점
7. [NLP] 언어모델의 평가지표 'Perplexity' 개념 및 계산방법
8. [NLP] Word2Vec: (1) 개념
9. [NLP] Word2Vec: (2) CBOW 개념 및 원리
10. [NLP] Word2Vec: (3) Skip-gram
11. [NLP] Word2Vec: (4) Negative Sampling
12. [NLP] 문서 유사도 분석: (1) 코사인 유사도(Cosine Similarity)
13. [NLP] 문서 유사도 분석: (2) 유클리디안 거리(Euclidean Distance)
14. [NLP] 문서 유사도 분석: (3) 자카드 유사도(Jaccard Similarity)
👨💻 맞춤 서비스
저희 AI/BigData 분석 솔루션 전문 브랜드 <데이터워너원 DATA101>에서는
맞춤형 데이터 수집부터 통계분석, 텍스트마이닝, AI 모델링, 논문작성을 지원해 드립니다 :)
자세한 내용은 아래 링크를 참고해 주세요!
데이터분석, 통계분석, 논문작성 지원해 드립니다. - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p>Python, SPSS, Tableau를 활용해 <strong>...
kmong.com
텍스트 데이터 분석/텍스트마이닝NLP 도와드립니다. - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p>대기업 AI/빅데이터 연구원 출신으로 구성된 법인 주식회사 유에프5는 Py...
kmong.com
유튜브 댓글 원하는 만큼 수집해 드립니다/웹 크롤링 - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p><strong style="font-size: 24px;&q...
kmong.com
모바일 앱 리뷰 크롤링/구글 플레이 스토어 - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p><strong>구글 플레이 스토어 앱 리뷰 1시간 안에 수집해 ...
kmong.com
오늘은 언어 모델의 평가지표인 Perplexity에 대해 알아봤습니다.
포스팅 내용에 오류가 있거나 보완할 점이 있다면 아래에 👇👇👇 댓글 남겨주시면 감사드리겠습니다 :)
그럼 오늘도 즐겁고 건강한 하루 보내시길 바랍니다.
고맙습니다😊
'AI & 빅데이터 > 자연어처리(NLP)' 카테고리의 다른 글
| [NLP] Word2Vec: (1) 개념 (0) | 2022.04.07 |
|---|---|
| [NLP] Word Embedding의 이해: 희소표현과 밀집표현 (1) | 2022.04.06 |
| [NLP] N-gram 언어 모델의 개념, 종류, 한계점 (0) | 2022.04.04 |
| [NLP] 언어모델(Language Model)의 개념 및 특징 (2) | 2022.03.31 |
| [NLP] TF-IDF 개념 및 계산 방법(+Python 코드) (6) | 2022.03.25 |



