
- Today
- Total
DATA101
[NLP] Word2Vec: (2) CBOW 개념 및 원리 본문
📚목차
1. 학습 데이터셋 생성
2. 인공신경망 모형
3. 학습 절차
4. CBOW vs Skip-gram
5. 한계점
들어가며
Word2Vec는 학습방식에 따라 크게 \(2\)가지로 나눌 수 있습니다: Continuous Bag of Words(CBOW)와 Skip-gram. CBOW는 주변 단어(Context Word)로 중간에 있는 단어를 예측하는 방법입니다. 여기서 중간에 있는 단어를 중심 단어(Center Word) 또는 타겟 단어(Target Word)라고 부릅니다. 반대로, Skip-gram은 중심 단어를 바탕으로 주변 단어들을 예측하는 방법입니다. 본 포스팅에서는 CBOW에 대해 다루고, 다음 포스팅에서 Skip-gram에 대해 자세히 다룹니다.
1. 학습 데이터셋 생성
CBOW에서 학습 데이터셋을 만드는 메커니즘에 대해 알아봅니다. 다음과 같은 예문을 활용해 보겠습니다.
"The fat cat sat on the table"
아래 사진은 실제 저희 집 반료묘 뚜니입니다 :)

CBOW는 주변 단어(context word)로부터 중심 단어(Center Word)를 예측하는 방법입니다. 즉, 예문에서 주변 단어인 ['The', 'fat', 'cat', 'on', 'the', 'table']로부터 'sat'을 예측하는 것이 CBOW의 역할입니다. 중심 단어를 예측하기 위하여 주변의 앞뒤 단어를 몇 개나 활용할지 범위를 결정해야 하는데, 이 범위를 윈도우(window)라고 부릅니다. 예를 들어, 윈도우의 크기가 \(2\)라고 하면, 중심 단어 'sat' 앞의 두 단어인 'fat', 'cat'과 뒤의 두 단어인 'on', 'the'를 활용합니다. 즉, 중심 단어 예측 시 윈도우의 크기가 \(n\)이라면 활용하는 주변 단어의 개수는 총 \(2n\)개입니다.
예측 모델 학습을 위한 데이터셋은 윈도우를 옆으로 한 단어씩 움직여(sliding) 주변 단어와 중심 단어의 세트를 변경하며 만드는데, 이 방법을 슬라이딩 윈도우(sliding window)라고 부릅니다. 윈도우의 크기를 \(2\)로 설정했을 때 앞서 사용한 예문을 바탕으로 학습 데이터셋을 만드는 과정은 아래의 그림 2와 같습니다.

Word2Vec의 입력과 출력은 모두 원-핫 벡터 형태여야 합니다. 슬라이딩 윈도우를 통해 중심 단어와 주변 단어의 선택을 순차적으로 변경했었는데, 이를 원 핫 벡터로 표현하면 아래의 표와 같습니다.
| 중심 단어 | 주변 단어 |
| [1, 0, 0, 0, 0, 0, 0] | [0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0] |
| [0, 1, 0, 0, 0, 0, 0] | [0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0] |
| [0, 0, 1, 0, 0, 0, 0] | [1, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 0] |
| [0, 0, 0, 1, 0, 0, 0] | [0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 0] |
| [0, 0, 0, 0, 1, 0, 0] | [0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 1] |
| [0, 0, 0, 0, 0, 1, 0] | [0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 0, 1] |
| [0, 0, 0, 0, 0, 0, 1] | [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 0] |
2. 인공신경망 모형
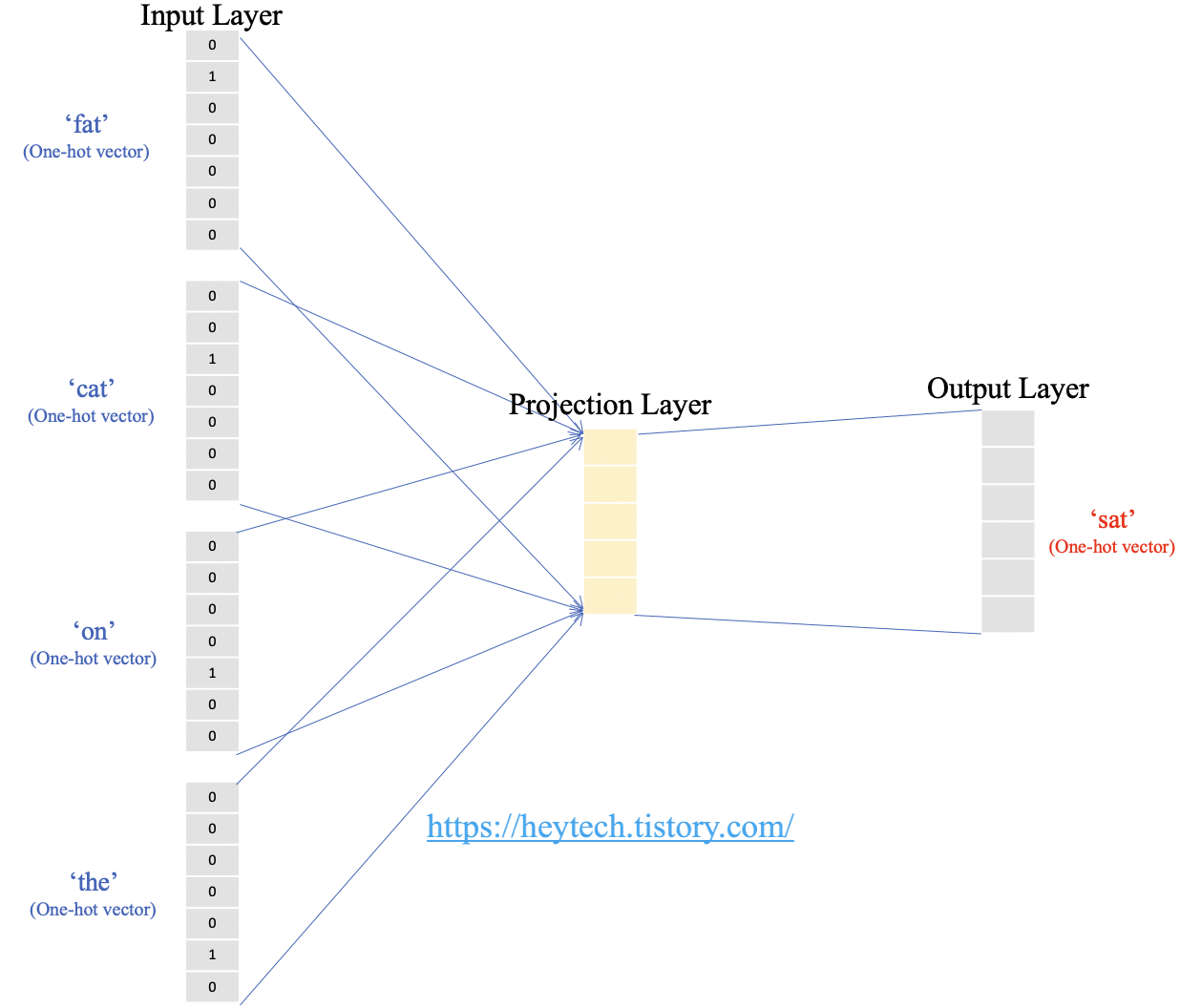
CBOW의 인공신경망(Artificial Neural Network, ANN)을 도식화하면 위의 그림 3과 같습니다. 입력층(input layer)에는 사용자가 지정한 윈도우 크기 범위 내 주변 단어들의 원-핫 벡터가 입력으로 들어갑니다. 입력값이 투사층(projection layer)을 통과하면 출력층(output layer)에서 중간 단어를 예측한 벡터가 출력됩니다.
위 그림 3에서 볼 수 있듯이, CBOW는 은닉층이 다수인 깊은 인공신경망(a.k.a., Deep learning) 모델이 아닌 단일 은닉층만 존재하는 얕은 신경망(shallow neural network) 모델입니다.
3. 학습 절차
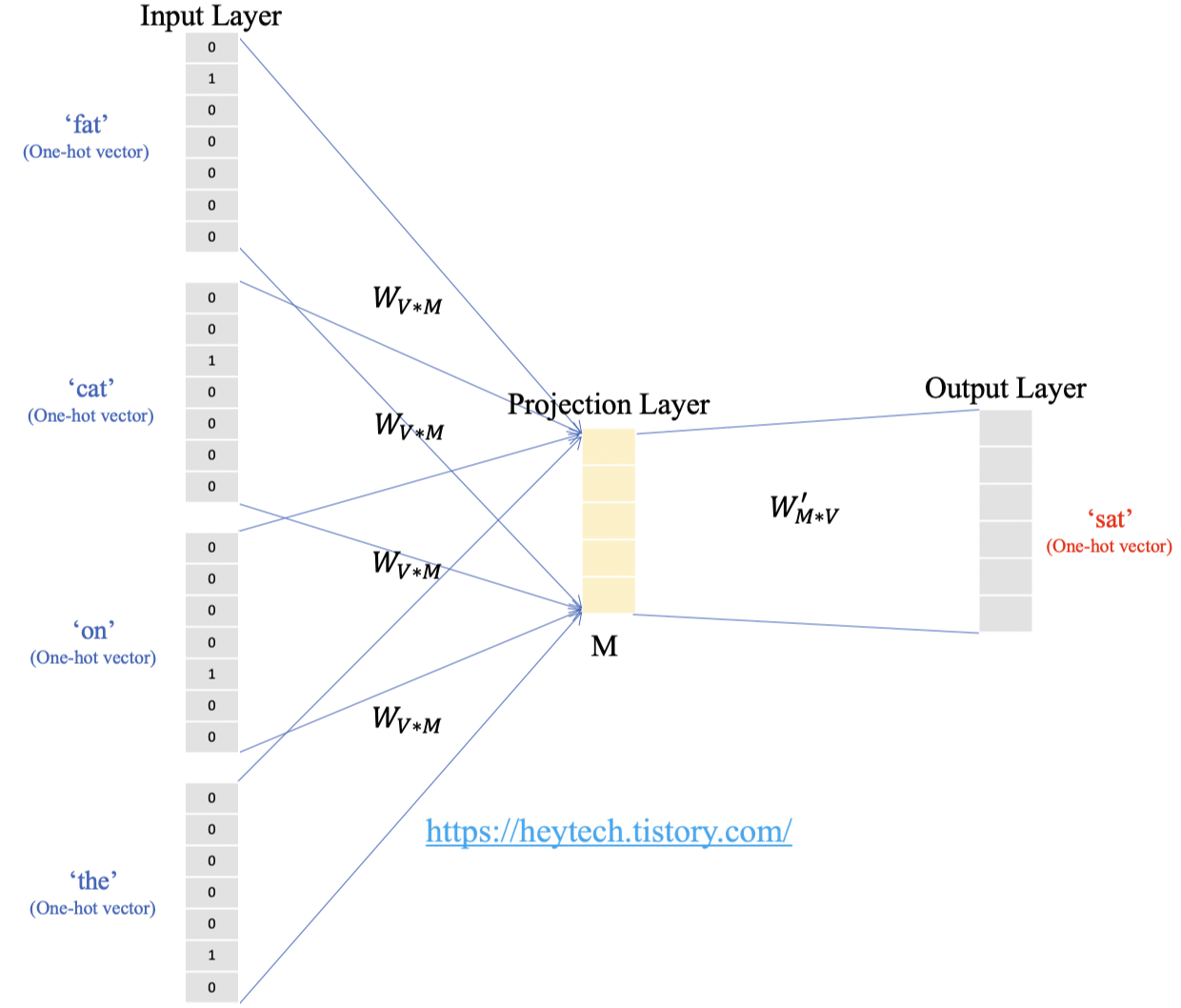
CBOW의 목표는 입력층과 투사층 사이의 가중치 행렬 \(W\)와 투사층과 출력층 사이의 가중치 행렬 \(W^{'}\)를 학습하며 주변 단어들로부터 중심 단어를 예측하는 것입니다(그림 4 참고). CBOW의 동작 메커니즘에 대해 자세히 알아봅니다.
3.1. 가중치 행렬
투사층의 크기가 \(M\)이고 단어 집합의 크기(Vocabulary)를 \(V\)라고 할 때, 입력층과 투사층 사이의 가중치 \(W\)는 \(VXM\) 크기의 행렬입니다. 반대로, 투사층과 출력층 사이의 가중치 \(W^{'}\)는 \(MXV\) 크기의 행렬입니다. 그림 4에서 사용된 예문의 단어 집합의 크기가 \(7\)이므로 입력 원-핫 벡터의 차원은 \(7\)입니다. 즉, 투사층의 크기\((M)\)가 \(5\)라고 하면, \(W\)는 \(7X5\) 행렬이며 \(W^{'}\)는 \(5X7\) 행렬입니다. 단, 두 가중치 행렬 \(W\)와 \(W^{'}\)는 전치(transpose) 관계가 아닌 서로 다른 행렬이며, 인공신경망 학습 전에는 두 행렬 모두 랜덤한 값을 갖습니다.
3.2. 룩업 테이블(Lookup Table)
룩업 테이블(Lookup Table)에 대해 알아봅니다. 단어 집합에서 \(i\)번째 단어의 원-핫 벡터에는 \(i\) 인덱스의 값만 \(1\)이고 나머지는 모두 \(0\)입니다. 즉, \(i\)번째의 단어 벡터와 가중치 행렬의 곱셈 결과는 사실상 가중치 행렬의 인덱스 \(i\) 행(row)을 그대로 읽어오는 것(=lookup)과 같습니다. 예를 들어보죠. 주변 단어의 원-핫 벡터를 \(x\)라고 하겠습니다. 아래 그림 5와 같이 'fat'이라는 단어의 인덱스는 [1]이므로 원-핫 벡터에 인덱스 [1] 값만 \(1\)이죠. 이 벡터를 가중치 행렬과 곱하면, 결괏값은 가중치 행렬에 인덱스 [1] 행을 그대로 가져온 것과 같습니다. 이러한 작업을 룩업 테이블이라고 부릅니다. 여기서 알 수 있는 것은 입력 벡터의 워드 임베딩(Word Embedding) 후 크기는 투사층의 크기 \(M\)과 같다는 점입니다.

3.3. 투사층 내 벡터의 평균
주변 단어들마다 가중치 행렬의 룩업 테이블 결괏값의 평균 벡터(\(v\))를 계산합니다.

수식은 아래와 같으며 \(n\)은 윈도우의 크기입니다.
$$ v = \frac{V_{fat}+V_{cat}+V_{on}+V_{the}}{2*n} $$
3.4. CBOW 학습
CBOW를 학습한다는 것은 모델의 예측값 \(\hat{y}\)과 실젯값 \(y\)의 차이를(=오차) 최소화할 수 있는 최적의 가중치 행렬을 찾는 것입니다. 이제 CBOW 학습의 과정을 알아보겠습니다.

평균 벡터 \(v\)를 투사층과 출력층 사이의 가중치 행렬 \(W^{'}\)과 곱합니다. 곱셈 결과로 얻어진 벡터를 \(z\)라 할 때, \(z\)는 입력층의 원-핫 벡터와 같은 차원이자 단어 집합의 크기인 \(V\)를 갖습니다(그림 7). \(z\) 벡터가 소프트맥스(softmax) 함수를 거치면 벡터 내 각 원소는 \(0\)과 \(1\) 사이의 실숫값을 갖고 모든 원소의 합은 \(1\)이 되는 스코어 벡터(score vector) \(\hat{y}\)를 얻을 수 있습니다. 스코어 벡터 내 각 원소의 값은 해당 단어가 중심 단어일 확률을 의미합니다. CBOW의 목표는 레이블 된(labeled) 중심 단어의 원-핫 벡터인 \(y\)와 스코어 벡터 \(\hat{y}\) 간의 오차를 최소화하는 것입니다. CBOW는 두 벡터의 차이를 계산하기 위해 손실함수(loss function)로써 크로스 엔트로피(Cross-entropy)를 사용합니다. 손실함수의 수식은 아래와 같습니다.
$$ cost(\hat{y}, y) = -\sum_{j=1}^{V}y_{j}log(\hat{y}) $$
역전파(Back Propagation)를 수행하면 가중치 행렬 \(W\), \(W^{'}\)이 학습되고, 모든 단어의 임베딩 벡터 값이 업데이트 됩니다. 즉, 모든 가중치의 집합을 \(\theta\)라고 하면 다음과 같이 가중치를 학습합니다.
$$ \hat{\theta} = \arg\min_{\theta}cost(\hat{y}, y) $$
4. CBOW vs Skip-gram
Word2Vec 방법 중 하나인 CBOW와 비교했을 때, Skip-gram이 성능이 우수하여 더욱 많이 사용되고 있습니다. 왜냐하면, 모델 학습 시 Skip-gram이 CBOW에 비해 여러 문맥을 고려하기 때문입니다. 앞선 예문을 다시 활용하여 살펴보겠습니다.
"The fat cat sat on the table"
CBOW와 Skip-gram 각각에 대해서 예측하는 단어마다 몇 번의 서로 다른 문맥을 고려했는지 확인해 보겠습니다.
4.1. CBOW
CBOW는 주변 단어로부터 오직 1개의 타겟 단어를 예측 및 학습합니다. Input과 Output 간의 관계를 나타내면 아래의 표와 같습니다.
| Input | Output |
| fat, cat | The |
| The, cat, sat | fat |
| The, fat, sat, on | cat |
| fat, cat, on, the | sat |
| cat, sat, the, table | on |
| sat, on, table | the |
| on, the | table |
즉, 단어를 예측 및 학습할 때 고려하는 문맥은 오직 1개뿐입니다. 아래의 표와 같이 말이죠. 예를 들어, 'sat'이라는 단어를 예측할 때는 'fat', 'cat', 'on', 'the'라는 주변 단어를 활용한 게 전부입니다.
| Word | Count |
| The | 1 |
| fat | 1 |
| cat | 1 |
| sat | 1 |
| on | 1 |
| the | 1 |
| table | 1 |
4.2. Skip-gram
Skip-gram은 타겟 단어를 바탕으로 여러 문맥 단어를 예측하고 학습합니다. Input과 Output 간의 관계를 나타내면 아래의 표와 같습니다.
| Input | Output |
| The | fat, cat |
| fat | The, cat, sat |
| cat | The, fat, sat, on |
| sat | fat, cat, on, the |
| on | cat, sat, the, table |
| the | sat, on, table |
| table | on, the |
위에서 예측 및 학습되는 출력값마다 고려하는 단어의 개수가 몇 개인지 계산해 보면 아래의 표와 같습니다. 이처럼, Skip-gram은 여러 문맥에 걸쳐 단어를 학습하기 때문에, 대부분의 상황에서 Skip-gram이 CBOW보다 좋은 성능을 보입니다.
| Word | Count |
| The | 2 |
| fat | 3 |
| cat | 4 |
| sat | 4 |
| on | 4 |
| the | 3 |
| table | 2 |
5. 한계점
Word2Vec의 한계점에 대해 다룹니다. Skip-gram뿐만 아니라 CBOW 역시 출력층에서 소프트맥스 함수를 거쳐 단어 집합 크기의 벡터와 실제 참값인 원-핫 벡터와의 오차를 계산합니다. 이를 통해 가중치를 수정하고 모든 단어에 대한 임베딩 벡터 값을 업데이트 합니다. 그런데, 만약 단어 집합의 크기\(V\)가 수만, 수십만 이상에 달하면 어떻게 될까요? 위와 같은 일련의 작업은 시간 소모가 큰 무거운 작업입니다. 즉, Word2Vec의 학습 모델 자체가 무거워집니다. 이를 해결하는 방법으로 Hierarchical Softmax와 Negative Sampling 방법이 있습니다. 이에 대한 내용은 다음 포스팅에서 자세히 다룹니다.
📚 참고할 만한 포스팅
1. [NLP] Bag of Words(BoW) 개념 및 실습
2. [NLP] 문서 단어 행렬(DTM) 개념 이해
3. [NLP] TF-IDF 개념 및 계산 방법
4. [NLP] Word Embedding의 이해: (1) 희소표현 및 밀집표현
5. [NLP] 언어모델(Language Model)의 개념 및 특징
6. [NLP] N-gram 언어 모델의 개념, 종류, 한계점
7. [NLP] 언어모델의 평가지표 'Perplexity' 개념 및 계산방법
8. [NLP] Word2Vec: (1) 개념
9. [NLP] Word2Vec: (2) CBOW 개념 및 원리
10. [NLP] Word2Vec: (3) Skip-gram 개념 및 원리
11. [NLP] Word2Vec: (4) Negative Sampling
👨💻 맞춤 서비스
저희 AI/BigData 분석 솔루션 전문 브랜드 <데이터워너원 DATA101>에서는
맞춤형 데이터 수집부터 통계분석, 텍스트마이닝, AI 모델링, 논문작성을 지원해 드립니다 :)
자세한 내용은 아래 링크를 참고해 주세요!
데이터분석, 통계분석, 논문작성 지원해 드립니다. - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p>Python, SPSS, Tableau를 활용해 <strong>...
kmong.com
텍스트 데이터 분석/텍스트마이닝NLP 도와드립니다. - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p>대기업 AI/빅데이터 연구원 출신으로 구성된 법인 주식회사 유에프5는 Py...
kmong.com
유튜브 댓글 원하는 만큼 수집해 드립니다/웹 크롤링 - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p><strong style="font-size: 24px;&q...
kmong.com
모바일 앱 리뷰 크롤링/구글 플레이 스토어 - 크몽
데이터워너원DATA101 전문가의 IT·프로그래밍 서비스를 만나보세요. <p><strong>구글 플레이 스토어 앱 리뷰 1시간 안에 수집해 ...
kmong.com
오늘은 Word2Vec 기법 중 CBOW의 개념 및 원리에 대해 알아봤습니다.
포스팅 내용에 오류가 있거나 보완할 점이 있다면 아래에 👇👇👇 댓글 남겨주시면 감사드리겠습니다 :)
그럼 오늘도 즐겁고 건강한 하루 보내시길 바랍니다.
고맙습니다😊
'AI & 빅데이터 > 자연어처리(NLP)' 카테고리의 다른 글
| [NLP] Word2Vec: (4) Negative Sampling 개념 및 소개 (0) | 2022.04.15 |
|---|---|
| [NLP] Word2Vec: (3) Skip-gram 개념 및 원리 (6) | 2022.04.14 |
| [NLP] Word2Vec: (1) 개념 (0) | 2022.04.07 |
| [NLP] Word Embedding의 이해: 희소표현과 밀집표현 (1) | 2022.04.06 |
| [NLP] 언어모델의 평가지표 'Perplexity' 개념 및 계산방법 (0) | 2022.04.05 |



