
DATA101
[NLP] LDA 토픽 모델링을 활용한 앱 리뷰 분석 프로젝트 본문
📌 Text 빅데이터분석 플랫폼 베타테스트 참가자 모집 중!(네이버페이 4만 원 전원 지급)

👋 안녕하세요, 코딩이 필요 없는 AI/빅데이터 분석 All in One 플랫폼 <DATA101> 개발팀입니다.
😊 저희 서비스를 사용해 보시고 경험담을 들려주세요 :)
💸 참여해 주신 "모든" 분들께 네이버페이 4만 원 쿠폰을 지급해 드립니다.
👨💻 참여 희망 시 카톡플러스친구 1:1 채팅 or 인스타그램 DM 부탁드립니다 :)
📆 참여기간 : 11/25(월)~11/29(금) 11:00~21:00 중 택1 (1시간 1타임)
👉 참여장소 : 강남역 인근 스터디카페 미팅Room
📍 소요시간 : 총 40분 내외(서비스 체험 및 인터뷰 포함)
✅ 참가조건 : Text 빅데이터 분석 업무 경험자
👉 참가 가능일정 조회하기 : https://url.kr/n8k8gu
- 카톡플친 : http://pf.kakao.com/_SxltHG/chat
- 인스타그램 : https://www.instagram.com/data101.official/
📚 목차
1. 개요
2. 데이터셋
3. LDA 토픽 모델링 개념
4. LDA 토픽 모델링 시각화
5. 전체 코드
6. 코드 설명
7. 결과 해석방법
8. 인사이트 도출
1. 개요
본 프로젝트에서는 건강관리 앱 리뷰 텍스트마이닝을 통해 고객의 니즈를 분석하고, 이를 바탕으로 건강관리 앱의 디자인 전략을 제안합니다. 국내 구글 플레이 스토어에서 건강관리 앱 424개에서 리뷰 54만 건을 수집하였으며, LDA 토픽 모델링을 통해 심층적으로 고객의 니즈를 분석하였습니다. 전체 코드 및 데이터셋은 Github에 업로드해 두었습니다.
2. 데이터셋
2.1. 사용자 리뷰
- 한국 구글 플레이 스토어 내 건강관리 앱 424개에서 리뷰 54만 건 수집(원본: Github)
- 데이터 수집 방법: 구글 플레이 스토어 리뷰 수집 크롤러 자체 개발(코드 및 설명: Github/블로그)
2.2. 전처리 목적 데이터셋
전처리 목적으로써 활용한 데이터셋은 다음과 같습니다. 해당 데이터셋은 Github 내 data 폴더에 있습니다.
1) 분석 제외 대상 앱 리스트
- 파일명: remove_app_list.xlsx
캐시워크와 같이 보상형 만보기 앱은 타 장르 앱보다 리뷰 개수가 월등히 많으며 리뷰 내용이 대부분 사용자 경험(UX)과는 거리가 먼 경우가 많았습니다. 이러한 앱 리뷰 전반적인 건강관리 앱의 UX 관련 정보를 추출하는 데 어려움을 주기 때문에 분석 대상에서 제외하였습니다. 즉, 보상형 만보기 앱 리뷰는 대부분 포인트 적립 에러, 상품 결제 에러와 같이 보상이나 기술적 에러가 차지하고 있기 때문에, 삼성 헬스, Noom과 같이 정통 건강관리 앱의 특성을 반영할 수 없다는 점을 고려하여 본 프로젝트의 연구 대상에서 제외하였습니다. 마찬가지로, ASMR, 명상 앱과 같이 정통 건강관리 앱과는 거리가 먼 앱을 리스트 업하여 분석에서 제외하였습니다.
2) 단어 치환 리스트
- 파일명: replace_list.xlsx
LDA 토픽 모델링은 빈출 어휘를 중심으로 결과를 제공하기 때문에 같은 의미를 가지는 단어는 하나의 단어로 통일하는 것이 텍스트에서 의미 분석(semantic analysis)을 효과적으로 수행하는 방법입니다. 예를 들어, '런닝', '러닝'은 모두 '달리기'와 같은 단어입니다. 사람은 해당 단어가 모두 같은 의미를 가진다고 판단할 수 있지만, 컴퓨터는 모두 다른 단어로 인식합니다. 이는 특정 의미의 단어가 빈출 어휘임에도 불구하고 각기 다른 단어로 사용됨에 따라 출현 횟수가 적게 카운트되어 키워드를 놓치는 경우를 야기할 수 있습니다. 따라서 LDA 토픽 모델링과 같이 단어의 출현 빈도가 중요한 텍스트마이닝 기법에서는 이와 같은 단어 치환 작업을 선행하는 것이 데이터 분석의 효과를 높이는 방법 중 하나입니다.
3) 불용어 리스트
- 파일명: stopword_list.xlsx
불용어(stopword)는 텍스트마이닝에서 빈출 되는 어휘이지만 사람들의 반응이나 의견과는 거리가 먼 서술어나 조사와 같은 단어를 말합니다. 예를 들어, '~입니다', '~이다', '~와', '~에서'와 같은 단어가 있습니다. 이러한 단어는 여러 리뷰에서 공통적으로 빈출 되는 단어이지만, 사용자 경험(UX)과는 전혀 연관되지 않습니다. 따라서 이러한 불용어를 전처리 단계에서 잘 정리해 줄 필요가 있습니다.
4) 1글자 키워드 리스트
- 파일명: one_char_list.xlsx
앞서 불용어는 텍스트마이닝을 통한 의미 분석에 있어서 불필요한 단어들의 집합이라고 했습니다. 문장을 토큰(token) 단위로 쪼개는 토큰화(tokenization) 작업 후, 1글자의 토큰은 일반적으로 모두 불용어로 취급합니다. 따라서 2글자 이상의 단어 중 불용어를 제거한 토큰만 활용하여 의미를 분석하는 경우가 많습니다. 이는 한국어 외 영어에서도 마찬가지입니다. 알파벳 1글자로는 큰 의미를 담기 어렵기 때문이죠. 하지만, 한국어에서는 1글자이지만 분석하는 도메인에 따라 키워드인 경우가 있습니다. 가령 '물', '돈', '땀'과 같이 건강관리 앱 서비스 이용 경험과 관련한 키워드가 출현하는 경우가 있습니다. 따라서, 전처리 단계에서는 이러한 1글자이지만 키워드인 단어는 예외적으로 전처리 단계에서 제거하지 않도록 추가적인 작업이 필요합니다.
3. LDA 토픽 모델링 개념
LDA 토픽 모델링에 대한 상세한 개념 설명은 이곳을 참고해 주세요. 본 포스팅에서는 간략한 개념 설명만 진행합니다. 토픽 모델링(Topic Modeling)은 텍스트 기반의 문서 데이터에서 핵심 주제(Topic)를 찾는 텍스트마이닝 방법론입니다. 특히, 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)은 토픽 모델링의 가장 대표적인 알고리즘입니다. 구체적으로, LDA 토픽 모델링은 확률 기반의 모델링 기법을 통해 방대한 양의 문서 데이터를 분석함으로써 문서 내에 어떤 토픽이, 어떤 비율로 구성되어 있는지 분석합니다(Blei et al., 2003). 또한, 토픽별로 어떤 키워드가 구성되었는지 정보를 제공하기 때문에, 키워드 조합을 통해 인사이트를 도출하는 데 효과적인 장점이 있습니다. 최근에는 LDA 토픽 모델링을 통해 SNS에서 유사한 토픽을 자동으로 분류하거나 항공사 온라인 리뷰를 분석하여 고객 니즈를 도출하는 등 다양한 분야에서 연구가 활발히 진행되고 있습니다(Lu et al., 2013, Kwon et al., 2021).
4. LDA 토픽 모델링 시각화
본 프로젝트에서는 리뷰 평점이 5점 만점인 것을 고려하여 4~5점을 긍정적 평가를 받은 리뷰로, 1~2점을 부정적 평가를 받은 리뷰로 분류하였습니다. 긍정적/부정적 평가를 받은 리뷰 그룹 각각에 대하여 LDA 토픽 모델링을 수행하고 시각화하면 아래의 그림 1, 2와 같습니다. 시각화 자료는 Github 내 result 폴더에 저장해 두었습니다.

5. 전체 코드
전체 코드 및 데이터셋은 아래의 Github에 업로드해 두었습니다.
https://github.com/park-gb/mHealthApp-review-textmining
GitHub - park-gb/mHealthApp-review-textmining: 건강관리 앱 리뷰 텍스트마이닝을 활용한 디자인 전략 연구:
건강관리 앱 리뷰 텍스트마이닝을 활용한 디자인 전략 연구: LDA 토픽 모델링을 중심으로. Contribute to park-gb/mHealthApp-review-textmining development by creating an account on GitHub.
github.com
6. 코드 설명
- 개발 환경: Python 3.8 (주피터 노트북)
- 가상 환경: Pipenv
본 섹션에서는 주피터 노트북 cell by cell로 작성한 코드에 대해 소개합니다.
6.1. 패키지 설치
1) 가상환경
- 가상 환경 pipenv 사용 시 아래 명령어를 통해 모든 필요 패키지 설치 가능
pipenv install2) KoNLPy Mecab 설치방법
- 명령어
bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)- 설치 오류 시 해결방법: https://heytech.tistory.com/395?category=453616
6.2. 패키지 import
import numpy as np
import pandas as pd
import warnings # 경고 메시지 무시
warnings.filterwarnings(action='ignore')
# 한국어 형태소 분석기 중 성능이 가장 우수한 Mecab 사용
from konlpy.tag import Mecab
mecab = Mecab()
from tqdm import tqdm # 작업 프로세스 시각화
import re # 문자열 처리를 위한 정규표현식 패키지
from gensim import corpora # 단어 빈도수 계산 패키지
import gensim # LDA 모델 활용 목적
import pyLDAvis.gensim_models # LDA 시각화용 패키지
from collections import Counter # 단어 등장 횟수 카운트6.3. 데이터셋 Load
리뷰 데이터를 불러옵니다(그림 3).
dataset_raw = pd.read_excel('./data/dataset_raw.xlsx')
dataset_raw.head()
6.4. 데이터 탐색
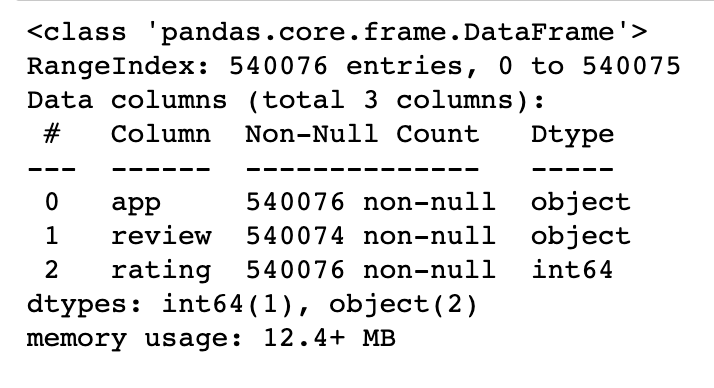
데이터셋에서 전반적으로 결측치 존재 여부, 데이터 타입, 데이터 개수를 확인합니다(그림 4).
dataset_raw.info()
6.5. 데이터 전처리
1) 결측치 확인
dataset_raw.isnull().sum()
2) 결측치 제거
# axis = 0: 결측치 포함한 모든 행 제거
dataset = dataset_raw.dropna(axis = 0)
dataset.isnull().sum()
3) 분석에서 제외할 앱 리뷰 삭제
분석에서 제외할 앱 리스트를 불러옵니다.
# 제외할 앱 리스트 Load
remove_app_list = pd.read_excel('./data/remove_app_list.xlsx')
remove_app_list.head()
분석에서 제외할 앱에 해당되는 리뷰는 분석에서 제외시킵니다.
for remove_app in remove_app_list['app']:
try:
dataset = dataset[dataset['app'] != remove_app]
except:
pass인덱스를 초기화합니다.
dataset.reset_index(drop = True, inplace=True)선별된 리뷰를 확인합니다. 아래의 그림 8처럼 약 26만 개의 리뷰가 1차적으로 선별되었습니다.
dataset
4) 전처리용 Dictionary 불러오기
전처리용 dictionary별 상세한 설명은 앞서 '2장 데이터셋' 부분에서 자세히 다루었기 때문에 데이터셋에 대한 추가 설명은 생략하겠습니다. 불용어 리스트를 불러옵니다.
stopword_list = pd.read_excel('./data/stopword_list.xlsx')
stopword_list.head()
데이터 치환할 리스트를 불러옵니다.
replace_list = pd.read_excel('./data/replace_list.xlsx')
replace_list.head()
한 글자인 키워드 리스트를 불러옵니다.
one_char_keyword = pd.read_excel('./data/one_char_list.xlsx')
one_char_keyword.head()
5) 단어 치환
같은 의미의 단어를 하나의 단어로 통일하는 작업입니다. LDA 토픽 모델링은 빈출 어휘를 중심으로 결과를 제공하기 때문에 단어를 통일할 필요가 있습니다. 아래와 같이 단어 치환을 위한 함수를 작성하였습니다.
def replace_word(review):
for i in range(len(replace_list['before_replacement'])):
try:
# 치환할 단어가 있는 경우에만 데이터 치환 수행
if replace_list['before_replacement'][i] in review:
review = review.replace(replace_list['before_replacement'][i], replace_list['after_replacement'][i])
except Exception as e:
print(f"Error 발생 / 에러명: {e}")
return review치환할 단어를 포함한 문장을 찾아 해당되는 모든 단어를 치환하고, 데이터셋 데이터프레임 내 새로운 칼럼(review_prep)에 저장합니다(그림 12).
dataset['review_prep'] = ''
review_replaced_list = []
for review in tqdm(dataset['review']):
review_replaced = replace_word(str(review)) # 문자열 데이터 변환
review_replaced_list.append(review_replaced)
dataset['review_prep'] = review_replaced_list
dataset.head()
6) 한글 외 텍스트 제거
숫자, 특수문자, 영문 등 서비스 경험과 관련된 의미를 추출해 내기 어려운 모든 문자열을 제거합니다.
review_removed = list(map(lambda review: re.sub('[^가-힣 ]', '', review), dataset['review_prep']))
dataset['review_prep'] = review_removed7) 평점 기준 데이터 분리
구글 플레이 스토어는 평점이 5점 만점입니다. 따라서 본 프로젝트에서는 4~5점을 긍정적인 평가를 받은 리뷰로, 1~2점을 부정적인 평가를 받은 리뷰로 분류하였습니다. 이는 서비스 이용 경험과 관련한 리뷰 내용이 긍정적인지, 부정적인지를 구분하기 위한 목적입니다.
# 긍정적 리뷰(평점 5점 만점 기준 4, 5점)
review_pos = dataset[(4 == dataset['rating']) | (dataset['rating'] == 5)]['review_prep']
# 부정적 리뷰(평점 5점 만점 기준 1, 2점)
review_neg = dataset[(1 == dataset['rating']) | (dataset['rating'] == 2)]['review_prep']8) 토큰화
본 프로젝트에서는 KoNLPy에서 속도 및 토큰화 측면에서 성능이 가장 우수한 Mecab 형태소 분석기를 활용합니다. 특히, 명사가 문장 내 맥락을 파악하는 데 핵심 형태소이며 빈출 어휘를 쉽게 파악할 수 있다는 장점이 있기 때문에, 리뷰에서 명사만 추출하였습니다.
review_tokenized_pos = list(map(lambda review: mecab.nouns(review), review_pos))
review_tokenized_neg = list(map(lambda review: mecab.nouns(review), review_neg))9) 불용어 제거
토큰화 후 토큰이 2글자인 경우 불용어에 해당되지 않는 토큰만 분석에 활용합니다. 토큰이 1글자인 경우에는 1글자 키워드 리스트에 포함되는 토큰만 분석에 활용합니다.
def remove_stopword(tokens):
review_removed_stopword = []
for token in tokens:
# 토큰의 글자 수가 2글자 이상인 경우
if 1 < len(token):
# 토큰이 불용어가 아닌 경우만 분석용 리뷰 데이터로 포함
if token not in list(stopword_list['stopword']):
review_removed_stopword.append(token)
# 토큰의 글자 수가 1글자인 경우
else:
# 1글자 키워드에 포함되는 경우만 분석용 리뷰 데이터로 포함
if token in list(one_char_keyword['one_char_keyword']):
review_removed_stopword.append(token)
return review_removed_stopwordreview_removed_stopword_pos = list(map(lambda tokens : remove_stopword(tokens), review_tokenized_pos))
review_removed_stopword_neg = list(map(lambda tokens : remove_stopword(tokens), review_tokenized_neg))10) 특정 토큰 개수의 리뷰 선별
일반적으로, 리뷰의 길이가 길수록 사용자 경험이나 기술적 문제 등 사용자 의견이 많이 내포되어 있을 가능성이 높습니다. 하지만, 오히려 지나치게 길이가 긴 리뷰는 주제 파악이나 리뷰 내 단어 간의 조합을 활용하여 특징을 추출하는 데 어려움이 있을 수 있습니다(Vasa et al., 2012). 따라서 본 프로젝트에서는 각 리뷰에서 추출된 명사의 개수가 3개 이상 15개 이하인 리뷰만을 분석에 활용하였습니다.
MIN_TOKEN_NUMBER = 3 # 최소 토큰 개수
MAX_TOKEN_NUMBER = 15 # 최대 토큰 개수def select_review(review_removed_stopword):
review_prep = []
for tokens in review_removed_stopword:
if MIN_TOKEN_NUMBER <= len(tokens) <= MAX_TOKEN_NUMBER:
review_prep.append(tokens)
return review_prepreview_prep_pos = select_review(review_removed_stopword_pos)
review_prep_neg = select_review(review_removed_stopword_neg)11) 전처리 결과 확인
최초에 수집한 54만 개의 리뷰 데이터 중 전처리 후 남은 데이터는 7.5만 개입니다.
review_num_pos = len(review_prep_pos)
review_num_neg = len(review_prep_neg)
review_num_tot = review_num_pos + review_num_neg
print(f"분석한 리뷰 총 개수: {review_num_tot}")
print(f"긍정적 리뷰: {review_num_pos}개({(review_num_pos/review_num_tot)*100:.2f}%)")
print(f"부정적 리뷰: {review_num_neg}개({(review_num_neg/review_num_tot)*100:.2f}%)")분석한 리뷰 총 개수: 74773
긍정적 리뷰: 63977개(85.56%)
부정적 리뷰: 10796개(14.44%)6.6. LDA 토픽 모델링
1) 하이퍼파라미터 튜닝
토픽의 개수와 학습 횟수는 하이퍼파라미터입니다. 본 프로젝트에서는 긍정적 리뷰와 부정적 리뷰 각각에서 토픽 10개씩을 추출합니다. 학습 횟수는 PASSES 옵션으로 변경하며 딥러닝에서 Epoch와 유사한 개념입니다. 전체 문서 데이터를 몇 번 학습할지 결정합니다.
NUM_TOPICS = 10 # 토픽 개수는 하이퍼파라미터
# passes: 딥러닝에서 Epoch와 같은 개념으로, 전체 corpus로 모델 학습 횟수 결정
PASSES = 152) 모델 학습 함수
def lda_modeling(review_prep):
# 단어 인코딩 및 빈도수 계산
dictionary = corpora.Dictionary(review_prep)
corpus = [dictionary.doc2bow(review) for review in review_prep]
# LDA 모델 학습
model = gensim.models.ldamodel.LdaModel(corpus,
num_topics = NUM_TOPICS,
id2word = dictionary,
passes = PASSES)
return model, corpus, dictionary3) 토픽별 단어 구성 출력 함수
토픽별로 구성된 단어의 비율을 출력하는 함수입니다.
def print_topic_prop(topics, RATING):
topic_values = []
for topic in topics:
topic_value = topic[1]
topic_values.append(topic_value)
topic_prop = pd.DataFrame({"topic_num" : list(range(1, NUM_TOPICS + 1)), "word_prop": topic_values})
topic_prop.to_excel('./result/topic_prop_' + RATING + '.xlsx')
display(topic_prop)4) 시각화 함수
시각화 함수는 result 폴더 내에 저장합니다.
def lda_visualize(model, corpus, dictionary, RATING):
pyLDAvis.enable_notebook()
result_visualized = pyLDAvis.gensim_models.prepare(model, corpus, dictionary)
pyLDAvis.display(result_visualized)
# 시각화 결과 저장
RESULT_FILE = './result/lda_result_' + RATING + '.html'
pyLDAvis.save_html(result_visualized, RESULT_FILE)5) 긍정적 리뷰 토픽 모델링
앞서 정의한 모델 학습, 토픽별 단어 구성 출력 함수, 시각화 함수를 활용하여 긍정적 리뷰와 부정적 리뷰 각각에 대하여 토픽 모델링 모델을 학습하고 시각화합니다. 여기서 토픽별 구성 단어(=NUM_WORDS)는 총 10개로 설정하였습니다.
model, corpus, dictionary = lda_modeling(review_prep_pos)
NUM_WORDS = 10토픽별 구성 단어 비율을 데이터프레임으로 출력합니다.
RATING = 'pos'
topics = model.print_topics(num_words = NUM_WORDS)
print_topic_prop(topics, RATING)
lda_visualize(model, corpus, dictionary, RATING)6) 부정적 리뷰 토픽 모델링
model, corpus, dictionary = lda_modeling(review_prep_neg)
NUM_WORDS = 10RATING = 'neg'
topics = model.print_topics(num_words = NUM_WORDS)
print_topic_prop(topics, RATING)
lda_visualize(model, corpus, dictionary, RATING)7. 결과 해석방법
LDA 토픽 모델링은 문서 데이터를 사용자가 지정한 토픽 개수만큼 토픽을 생성하고, 각 토픽별로 어떤 키워드가, 어떤 비율로 구성되는지 정보를 제공합니다. 즉, 토픽의 구체적인 주제는 사용자가 직접 키워드를 통해 파악해야 합니다. 예를 들어, '웨이트', '기록', '편리', '일지'와 같은 키워드로 구성된 토픽은 '운동 기록' 기능과 관련한 주제일 가능성이 높습니다. 이처럼, LDA 토픽 모델링 기법은 토픽 내 어떤 키워드들이, 어떤 비율로 구성되었는지 파악하는 것이 중요합니다. 이러한 특징을 고려하여 pyLDAvis를 통해 시각화한 자료를 효과적으로 해석하는 방법에 대해 다룹니다.
7.1. Relevance(\(\lambda\))
아래의 그림 15 내 우측 상단 sliding bar를 통해 Relevance(\(\lambda\))를 조절할 수 있습니다. Relevance는 특정 토픽에서 어떤 단어의 출현 빈도와 전체 문서에서 그 단어의 출현 빈도를 균형 있게 조정하는 하이퍼 파라미터입니다. 즉, 특정 토픽에서 출현 빈도가 높게 나타난 어떤 단어가 있을 때, 그 단어가 다른 토픽과 해당 토픽을 구분하는 키워드이기 때문에 출현 빈도가 높은 것인지, 아니면 단순히 여러 문서 데이터에서 널리 사용되는 단어이기 때문에 출현 빈도가 높았던 것인지 명확히 구분할 수 있도록 도와주는 파라미터입니다.
Relevance 값은 \(0\)부터 \(1\) 사이의 값으로, \(0\)에 가까울수록 전체 문서에서 출현 횟수는 적더라도 해당 토픽을 다른 토픽과 차별성 있게 구분할 수 있는 단어인지에 집중합니다. 반대로, Relevance 값이 \(1\)에 가까울수록 특정 토픽을 구성하는 키워드보다는 전체 문서 데이터에서 얼마나 빈출 되는 키워드일 가능성이 높다는 의미입니다. 예를 들어, 건강관리 앱 리뷰 데이터에서는 '운동'이라는 단어가 여러 리뷰에서 등장할 확률이 굉장히 높습니다. 따라서 단순히 '운동'이라는 단어만으로는 어떤 토픽을 다른 토픽과 명확하게 구분짓기는 어렵습니다. 이러한 경우에 Relevance를 \(0\)에 가깝게 설정하면 많은 리뷰에서 빈출되는 '운동'이라는 단어의 중요도(importance)에 페널티를 부여할 수 있습니다. 이를 통해 '운동'이라는 단어는 해당 토픽에만 유독 많이 등장한 것이 아닌 전체 문서에서 널리 사용되는 단어임을 파악할 수 있습니다. Sievert & Shirley (2014) 연구에 따르면, Relevance 값은 \(0.6\)이 가장 효과적인 것으로 알려져 있습니다. 하지만, 이 값은 항상 정답이 아닙니다. 각자의 연구 도메인, 데이터셋 등에 따라 최적의 Relevance 값은 다를 수 있기 때문입니다.
7.2. 토픽 및 키워드 구성
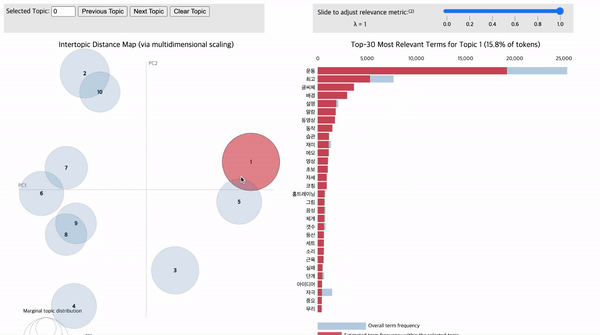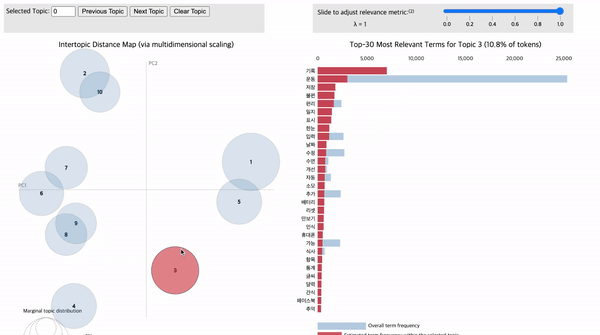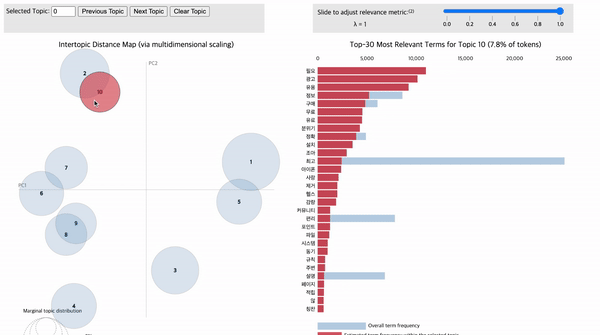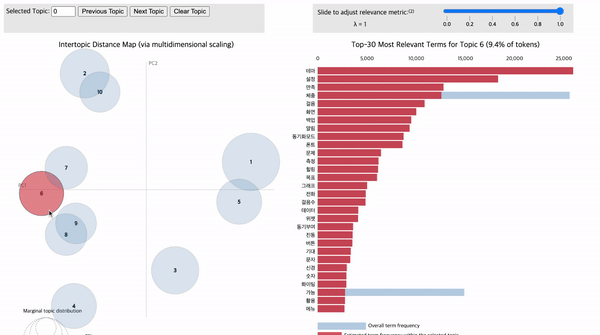
아래의 그림 16 내 좌측 원이 모두 각각의 토픽입니다. 원과 원 사이의 거리는 서로 얼마나 유사한 토픽인지를 의미합니다. 즉, 서로 가까이 붙어있는 원일 수록 유사한 토픽입니다. 원이 클수록 토픽에 해당되는 단어(=토큰)의 개수가 많다는 것을 의미합니다. 원에 마우스를 가져다 대면 우측에 해당 토픽을 구성하는 단어가 전체 문서 데이터 대비 현재 토픽의 키워드로 구성되었는지 비율을 알려줍니다. 또한, 전체 문서 데이터의 단어 대비 해당 토픽이 구성하는 단어들의 비율을 제공합니다. 이처럼 토픽별로 어떤 단어들이, 어떤 비율로 구성되어 있는지 파악함으로써 토픽별 주제를 유추할 수 있으며, 나아가 전체 문서 데이터에 어떤 토픽이, 어떤 비율로(=중요도) 구성되어 있는지 파악할 수 있습니다.
8. 인사이트 도출
시각화한 결과를 바탕으로 사용자 니즈를 분석해 봅니다.
8.1. 긍정적 리뷰 분석
먼저, 긍정적 리뷰를 토픽 모델링한 결과는 아래의 그림 17과 같습니다.

1) 운동 동작 설명 기능
1번 토픽에 '운동', '설명', '동영상', '동작'과 같은 단어가 빈출된 것을 확인할 수 있습니다. 이는 운동 동작을 영상을 활용하여 설명해 주는 기능이 긍정적인 평가를 받았다고 볼 수 있습니다. 따라서 건강관리 앱 서비스 기획 시 영상 기반의 운동 동작 강의 콘텐츠를 고려해 볼 수 있겠습니다.
2) 식단 기록 기능
4번 토픽에 '사진', '식단', '조절', '저장', '일기장'과 같은 단어가 빈출되었습니다. 이를 통해 식단을 사진으로 찍어 저장하는 등의 식단 기록 기능이 일기장과 같은 역할을 함으로써 식단을 조절하는 데 긍정적인 효과를 주었다고 볼 수 있습니다. 컴퓨터 비전(Computer Vision) 기술을 통해 음식 사진을 통해 어떤 음식을, 얼마나 먹었는지 분석할 수 있습니다. 이러한 기술을 활용하면 사용자가 일일이 식단 정보를 기록해야 하는 번거로움을 덜어줄 수 있어 편의성 측면에서 긍정적인 사용자 경험을 제공할 수 있을 것으로 기대됩니다.
3) 운동 일지 기능
10번 토픽에 '운동', '일지', '정리', '프로그램', '재미', '거리', 계획', '최고'와 같은 단어가 빈출되었습니다. 이는 운동 일지 기록을 통한 운동 계획 세우기, 운동량(이동거리) 측정을 통한 운동량 확인 기능이 운동에 대한 흥미와 동기부여를 제공하는 데 긍정적인 효과를 미친 것으로 해석할 수 있습니다. 이처럼, 사용자가 운동량, 운동 종류를 기록하도록 도울 수 있는 운동 일지 기능을 앱 서비스에 추가함으로써 꾸준한 운동과 앱 사용을 증진하는 데 도움이 될 것으로 기대됩니다.
8.2. 부정적 리뷰 분석
부정적 리뷰를 토픽 모델링한 결과는 아래의 그림 18과 같습니다.

1) 웨어러블 연동 오류
2번 토픽에 '연동', '밴드', '알림', '오류', '블루투스', '웨어러블'과 같은 단어가 빈출된 것을 확인하실 수 있습니다. 스마트 워치나 스마트 밴드와 같은 블루투스 기반의 웨어러블 기기와의 연동 오류가 많은 사용자들로부터 부정적인 평가를 받았다고 볼 수 있습니다. 스마트 워치는 운동 기록을 자동으로 트래킹 할 뿐만 아니라 일상 생활에서도 문자 메시지 혹은 앱 서비스의 푸시 알림 등을 편리하게 수신할 수 있어 최근 큰 각광을 받고 있습니다. 따라서, 건강관리 앱 설계 시 웨어러블 디바이스와의 연동 정확성을 높이기 위한 기술적 개선이 반드시 필요합니다.
2) 자동 유료 구독 컴플레인
3번 토픽에 '결제', '환불', '취소', '요청', '자동', '구독', '무료'와 같은 단어가 빈출 된 것을 확인할 수 있습니다. 이는 일부 건강관리 앱에서 초기 1~3개월간은 무료로 서비스를 제공하다가 유예기간 이후부터는 사용자의 추가적인 동의 없이 유료 구독 서비스로 전환하는 운영 방식 때문에 발생한 다수의 컴플레인임을 알 수 있습니다. 이러한 서비스 운영 방침에 많은 사용자가 즉시 구독 취소와 환불을 요청하는 리뷰가 많은 것을 알 수 있습니다. 따라서 건강관리 앱 운영 방식에 있어서, 유료 구독 서비스로 전환되기 이전에 사용자에게 추가로 결제 의사를 묻고, 이에 동의하는 경우에만 결제와 유료 서비스를 제공하는 방식으로 전환할 필요가 있습니다.
3) 운동 트래킹 정확도 이슈
10번 토픽에서 '동기화모드', '걸음', '문제', '걸음수', '측정', '데이터'와 같은 단어가 빈출된 것을 확인할 수 있습니다. 이는 걸음수와 같은 운동 트래킹의 정확도 이슈와 관련된 부정적인 피드백이 많다는 것을 알 수 있습니다. 예를 들어, 앱에서는 1만 걸음을 걸었다고 나오지만, 스마트 워치에서는 5천 걸음밖에 카운트하지 않은 경우가 해당됩니다. 사용자는 이러한 운동 트래킹의 낮은 정확도 때문에 서비스 전체의 신뢰도를 낮게 평가할 수 있습니다. 따라서 건강관리 앱 설계 시 앱뿐만 아니라 웨어러블 디바이스 환경에서도 운동 트래킹의 정확도를 꾸준히 개선할 필요가 있습니다.
포스팅 내용에 오류가 있거나 보완할 사항이 있다면 아래에 댓글 남겨주세요 :)
그럼 오늘도 즐겁고 건강한 하루 보내시길 바랍니다😊
고맙습니다 :D
'AI & 빅데이터 > 자연어처리(NLP)' 카테고리의 다른 글
| Mecab 설치 에러 해결하기: "Exception: Install MeCab in order to use it: http://konlpy.org/en/latest/install/" (3) | 2022.06.01 |
|---|---|
| [NLP] Pretrained 언어모델 기반 한국어 경제 뉴스 기사 감정 분류 (3) | 2022.05.31 |
| [NLP] 문서 유사도 분석: (3) 자카드 유사도(Jaccard Similarity) (0) | 2022.04.20 |
| [NLP] 문서 유사도 분석: (2) 유클리디안 거리(Euclidean Distance) (0) | 2022.04.19 |
| [NLP] 문서 유사도 분석: (1) 코사인 유사도(Cosine Similarity) (0) | 2022.04.18 |



