
DATA101
[알고리즘] 계수 정렬에 대해 알아보자! (+Python 구현) 본문
본 포스팅에서는 계수 정렬 알고리즘에 대해 알아봅니다.
📚 목차
1. 계수 정렬이란?
2. 계수 정렬의 동작 과정
3. 계수 정렬의 구현(Python)
4. 계수 정렬의 시간 복잡도
1. 계수 정렬이란?
계수 정렬은 데이터 개수가 많더라도 매우 빠르게 동작하는 정렬 알고리즘 중 하나로서 리스트가 모두 정수 형태로 표현되어 있고 가장 작은 데이터와 가장 큰 데이터의 차이가 1백만(1,000,000) 이하일 때 효과적으로 동작합니다. 이처럼 특정 조건이 부합할 때만 동작하는 이유는 계수 정렬을 활용할 때는 가장 작은 데이터부터 가장 큰 데이터까지 모든 범위의 데이터를 담을 수 있는 크기의 리스트를 선언해야 하기 때문입니다. 예를 들어, 가장 작은 데이터와 가장 큰 데이터의 차이가 1,000,000이라면 총 1,000,001개의 데이터를 담을 수 있는 리스트를 선언해야 합니다. 여기서 1개를 추가한 이유는 0부터 1,000,000까지는 총 1,000,001개이기 때문입니다.
2. 계수 정렬의 동작 과정
이제 계수 정렬의 구체적인 동작 과정을 알아보도록 하겠습니다.
1️⃣ 가장 작은 데이터부터 가장 작은 데이터까지 모두 담을 수 있는 리스트를 생성합니다.
2️⃣ 리스트 내 모든 값을 0으로 초기화합니다.
3️⃣ 정렬할 리스트 내 데이터 값과 1️⃣에서 생성한 리스트에서 일치하는 인덱스에 해당하는 값을 1씩 증가시키는 과정을 반복합니다.
4️⃣ 데이터 확인이 모두 끝났다면 1️⃣에서 생성한 리스트 내 인덱스 순서대로 인덱스에 부여된 값만큼 반복하여 출력합니다.
위 과정처럼 계수 정렬은 앞서 다룬 선택 정렬, 삽입 정렬, 퀵 정렬과 같이 데이터 간의 값을 비교하며 위치를 변경하는 정렬 방법인 비교 기반의 정렬 알고리즘이 아닙니다. 계수 정렬의 동작 과정을 더욱 직관적으로 이해할 수 있도록 실제 예시를 통해 알아보겠습니다.
0부터 9까지 총 10가지 데이터가 중복을 포함하여 아래 그림 1과 같이 있을 때 계수 정렬을 통해 오름차순으로 정렬해 보겠습니다.

1) 데이터 비교
(1) 먼저 가장 작은 값인 0부터 가장 큰 값인 9까지 모든 범위를 포함할 수 있는 크기 10인 리스트를 생성하고, 리스트 내 모든 인덱스의 데이터가 0이 되도록 초기화하겠습니다. 이제 그림 1 의 리스트 내 좌측부터 차례대로 데이터 값과 일치하는, 앞서 생성한 리스트 내 인덱스의 데이터를 1씩 추가해 줍니다.

여기서 편의상 현재 비교하는 데이터를 파란색으로 표현하고 비교가 끝난 값은 회색으로 표현하겠습니다.
(2) 좌측 맨 앞 데이터인 6과 생성된 리스트 내 인덱스 6에 해당하는 데이터를 1 추가해 줍니다.
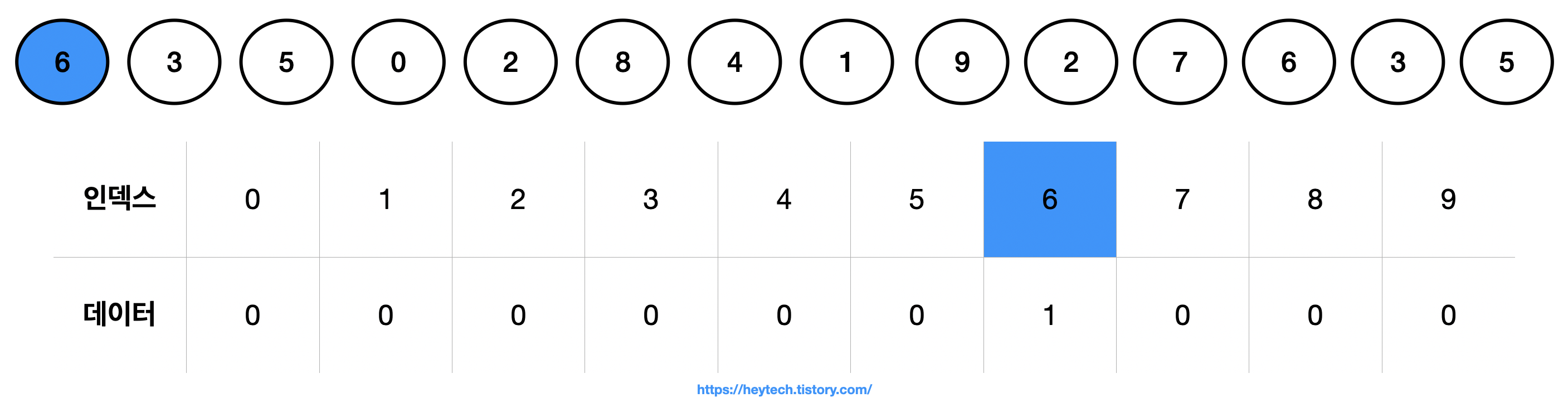
(3) 그다음으로 데이터 3과 인덱스 3에 해당하는 데이터를 1 추가해 줍니다.
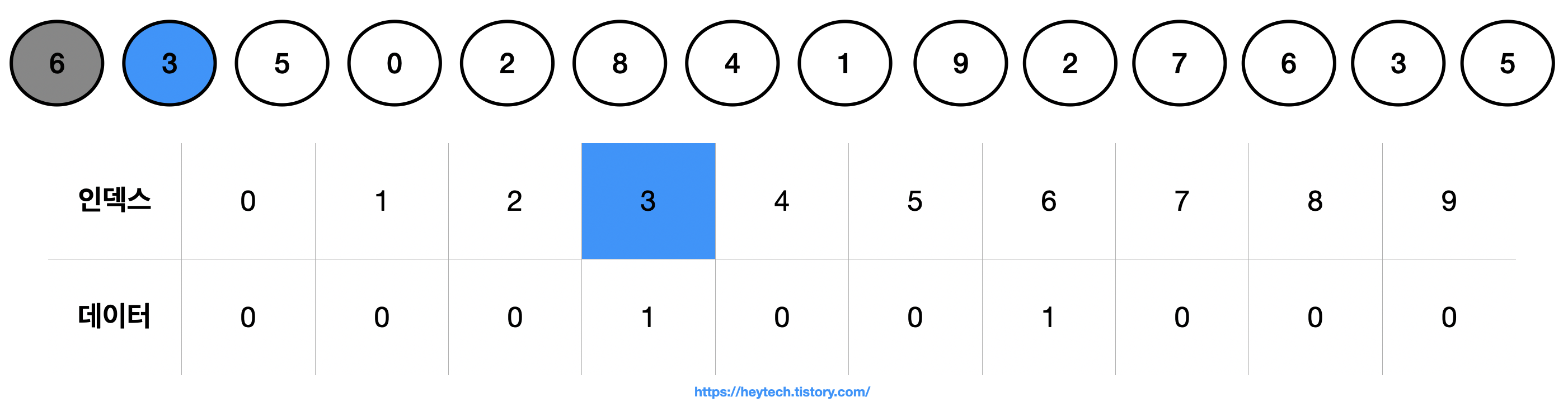
(중략)
위와 같은 방법으로 모든 데이터를 비교하면 아래와 같습니다. 이는 주어진 리스트에 각 데이터가 몇 개 포함되어 있는지 기록한 것과 같습니다. 예를 들어, 인덱스 3의 데이터가 2이므로 3은 리스트에 총 2개 포함되어 있다고 해석할 수 있습니다.

2) 정렬된 데이터 출력
(1) 정렬된 결괏값을 확인하기 위해서는 앞서 기록한 리스트에서 인덱스를 데이터 값만큼 출력하면 됩니다. 예를 들어, 인덱스 0의 데이터는 1이므로 0을 1번만 출력합니다.
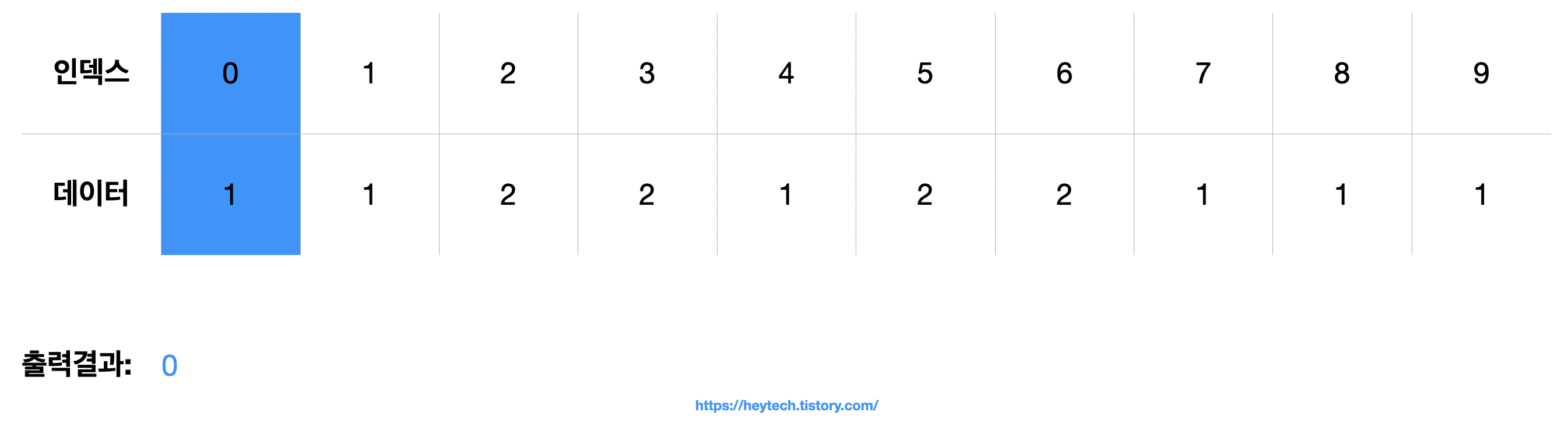
(2) 다음으로 인덱스 1의 데이터 값이 1이므로 1을 1번만 출력합니다.

(3) 다음으로 인덱스 2의 데이터 값이 2이므로 2를 2번 출력합니다.
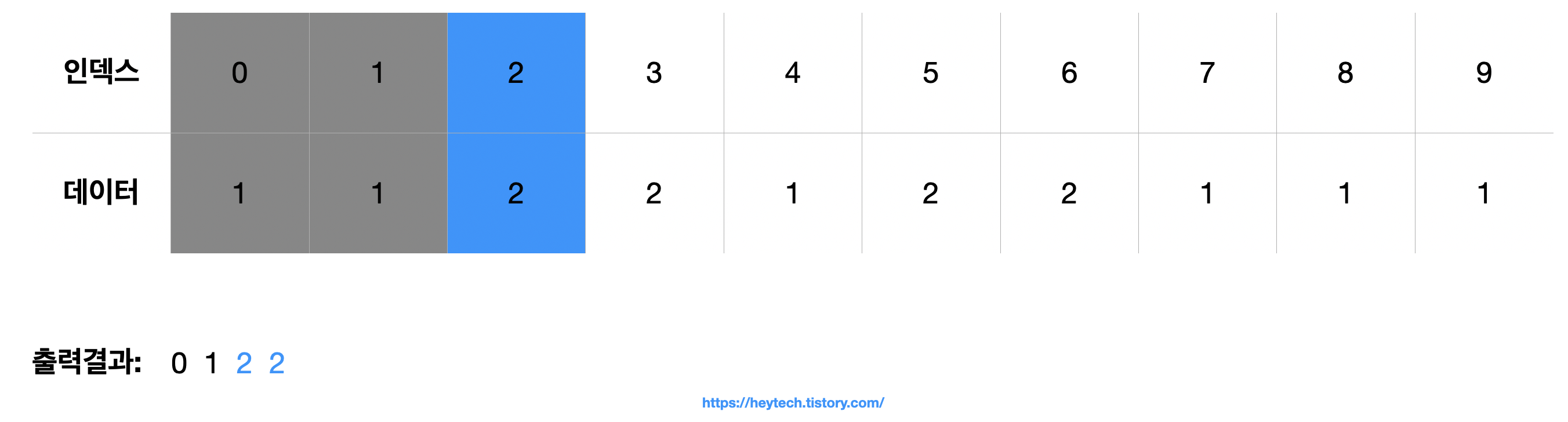
(중략)
위와 같은 방법으로 데이터를 출력하면 결과는 다음과 같습니다.

3. 계수 정렬의 구현(Python)
앞서 살펴본 계수 정렬의 예시를 실제로 파이썬을 통해 구현해 보겠습니다.
arr = [6, 3, 5, 0, 2, 8, 4, 1, 9, 2, 7, 6, 3, 5]
# 모든 범위를 포함하는 리스트 선언하고 동시에 모든 값은 0으로 초기화
cnt = [0] * (max(arr) + 1)
for i in range(len(arr)):
# 인덱스별로 일치하는 데이터 개수만큼 값 증가
cnt[arr[i]] += 1
# 인덱스 순서대로 데이터 출력
for i in range(len(cnt)):
# 인덱스별 데이터 개수만큼 인덱스 출력
for j in range(cnt[i]):
print(i, end = ' ')출력 결과
0 1 2 2 3 3 4 5 5 6 6 7 8 94. 계수 정렬의 시간 복잡도
계수 정렬은 앞에서부터 데이터를 일일이 확인하며 일치하는 인덱스의 값을 1씩 증가시키며, 리스트 내 최댓값의 크기만큼 반복문을 통해 정렬된 결과를 출력합니다. 따라서 모든 데이터가 양의 정수로 구성되어 있는 N개의 데이터가 있고 최댓값이 K라고 하면, 계수 정렬의 시간 복잡도는 O(N + K) 입니다. 따라서 데이터 개수가 한정적인 경우에는 정렬 알고리즘 중에서 가장 빠르다고 할 수 있습니다.
5. 계수 정렬의 공간 복잡도
계수 정렬은 초기에 가장 작은 데이터부터 가장 큰 데이터까지 모두 포함할 수 있는 크기의 리스트를 생성해야 한다고 말씀드렸습니다. 이에 경우에 따라서 공간 복잡도 측면에서 심각한 비효율성을 야기할 수 있습니다. 예를 들어, 데이터가 0과 999,999로 딱 2개만 존재한다고 가정해 보겠습니다. 이런 경우에도 계수 정렬을 활용하기 위해서는 크기가 100만인 리스트를 생성해야 합니다.
즉, 계수 정렬은 항상 사용할 수는 없는 알고리즘으로서 동일한 값을 가지는 데이터가 여러 개 있고 데이터의 크기가 한정되어 있을수록 효율적으로 동작합니다. 예를 들어, 100점 만점인 시험 성적을 기준으로 어떤 학교 학생들의 이름을 정렬할 때는 100점이나 90점 등 특정 점수를 맞은 학생이 여러 명일 수 있기 때문에 계수 정렬을 활용하면 빠르게 정렬을 수행할 수 있을 것입니다.
이처럼 계수 정렬은 데이터의 크기가 제한적인 경우에는 데이터 개수가 많을 때에도 효율적으로 정렬할 수 있습니다. 일반적으로 데이터의 개수가 1,000만 개 이하인 경우, 데이터 개수가 총 N개이고 최댓값이 K일 때 계수 정렬 알고리즘의 공간 복잡도는 O(N+K) 입니다.
📚참고할 만한 포스팅
1. [알고리즘] 선택 정렬에 대해 알아보자! (+Python 구현)
2. [알고리즘] 삽입 정렬에 대해 알아보자! (+Python 구현)
3. [알고리즘] 퀵 정렬에 대해 알아보자! (+Python 구현)
4. [알고리즘] 계수 정렬에 대해 알아보자! (+Python 구현)
5. [파이썬] 내장 함수를 활용한 데이터 정렬하기! (sorted, sort 함수)
포스팅 내용에 오류가 있을 경우 댓글 남겨주시면 감사드리겠습니다.
그럼 오늘도 즐거운 하루 보내시길 바랍니다 :)
고맙습니다.
'알고리즘 > 이론' 카테고리의 다른 글
| [알고리즘] 순차 탐색(Sequential Search)에 대해 알아보자!(+Python 구현) (0) | 2021.03.16 |
|---|---|
| [알고리즘] 정렬 알고리즘 문제 풀이 전략! (0) | 2021.03.15 |
| [알고리즘] 퀵 정렬에 대해 알아보자! (+Python 구현) (0) | 2021.03.12 |
| [알고리즘] 삽입 정렬에 대해 알아보자! (+Python 구현) (2) | 2021.03.11 |
| [알고리즘] 선택 정렬에 대해 알아보자! (+Python 구현) (0) | 2021.03.10 |



