
목록알고리즘 (56)
DATA101
 [자료구조] 우선순위 큐(Priority Queue)에 대해 알아보자!(+Python 구현)
[자료구조] 우선순위 큐(Priority Queue)에 대해 알아보자!(+Python 구현)
📚 목차 1. 우선순위 큐(Priority Queue)란? 2. 힙(Heap) 자료구조 2.1. 힙 자료구조란? 2.2. 우선순위 큐 구현 방식: 리스트 vs 힙 3. 힙 기반의 우선순위 큐 구현(Python) 3.1. heapq 라이브러리 소개 3.1.1. 힙 원소 추가(heappush) 3.1.2. 힙 원소 삭제(heappop) 3.1.3. 리스트를 힙으로 변경(heapify) 3.2. 힙 기반의 우선순위 큐 구현 예시 1. 우선순위 큐(Priority Queue)란? 우선순위 큐는 말 그대로 우선순위가 가장 높은 데이터를 가장 먼저 추출하는 자료구조입니다. 일반적으로 큐(Queue) 자료구조는 선입선출 방식으로서 가장 먼저 삽입된 데이터를 가장 먼저 추출합니다. 간단하게 특징이 유사한 자료구조들의 ..
 [자료구조] 그래프 자료구조에 대해 알아보자!(노드, 간선, 루트 노드, 깊이, 높이, 차수)
[자료구조] 그래프 자료구조에 대해 알아보자!(노드, 간선, 루트 노드, 깊이, 높이, 차수)
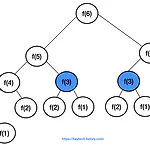
본 포스팅에서는 그래프(graph) 자료구조에 대해 알아봅니다. 그래프 자료구조의 구성 그래프는 그림 1 과 같이 노드(Node)와 간선(Edge)으로 표현됩니다. 이때 노드는 정점(Vertext)이라고도 불립니다. 일반적으로 노드와 간선은 각각 도시와 도시를 잇는 도로를 예시로 많이 표현됩니다. 즉, A 도시(노드)와 B 도시(노드)가 있을 때, A 도시에서 B 도시로 이동하기 위해 도로(간선)를 거친다고 생각하시면 노드와 간선에 대한 이해가 쉬울 것입니다. 그래프 탐색? 그래프 탐색이란 하나의 노드에서 시작해서 다른 노드들을 방문하는 것을 의미합니다. 노드 인접? 두 노드가 간선으로 연결되어 있다면, '두 노드는 인접(Adjacent)해 있다'라고 말합니다. 그래프 자료구조 관련 용어 정리 그래프(트..
 [알고리즘] 다이나믹 프로그래밍(DP)에 대해 알아보자! (+Python 구현)
[알고리즘] 다이나믹 프로그래밍(DP)에 대해 알아보자! (+Python 구현)
본 포스팅에서는 다이나믹(동적) 프로그래밍에 대해 알아봅니다. 📚 목차 1. 다이나믹 프로그래밍이란? 2. 다이나믹 프로그래밍 예제 3. 재귀함수 기반 구현 3.1. 소스코드 3.2. 문제점 3.2.1. 연산 복잡성 3.2.2. 문제 발생의 원인 3.2.3. 문제 해결 방안 4. 다이나믹 프로그래밍 기반 구현 4.1. 탑 다운 방식(재귀함수 활용) 4.1.1. 메모이제이션이란? 4.1.2. 소스코드 4.1.3. 특징 4.2. 바텀 업 방식(반복문 활용) 4.2.1. 소스코드 4.2.2. 특징 1. 다이나믹 프로그래밍이란? 다이나믹(동적) 프로그래밍은 큰 문제를 작은 문제로 나누어 연산 속도와 메모리를 최대한으로 활용하기 위한 기법입니다. 특정 값을 얻기 위해 매번 같은 결과를 반환하는 연산을 굳이 반복해..
 [알고리즘] 이진 탐색(Binary Search)에 대해 알아보자!(+Python 구현)
[알고리즘] 이진 탐색(Binary Search)에 대해 알아보자!(+Python 구현)
본 포스팅에서는 이진 탐색(Binary Search) 알고리즘에 대해 알아봅니다. 📚 목차 1. 이진 탐색이란? 2. 이진 탐색의 동작 과정 3. 이진 탐색의 시간 복잡도 4. 이진 탐색 구현(Python) 1. 이진 탐색이란? 이진 탐색은 탐색의 범위를 절반씩 좁혀가며 데이터를 탐색하는 알고리즘입니다. 이진탐색 알고리즘은 리스트 내 데이터가 어느 정도 정렬되어 있어야만 사용 가능하며 데이터가 무작위로 정렬되어 있다면 사용할 수 없습니다. 이진 탐색 알고리즘은 입력 데이터가 많거나(e.g., 1,000만 개 이상) 탐색 범위의 크기가 매우 넓을 때(e.g., 1,000억 이상) 효과적으로 문제를 해결할 수 있습니다. 2. 이진 탐색의 동작 과정 이진 탐색의 동작 과정에 대해 이해하기 위해서는 순차 탐색(..
 [알고리즘] 순차 탐색(Sequential Search)에 대해 알아보자!(+Python 구현)
[알고리즘] 순차 탐색(Sequential Search)에 대해 알아보자!(+Python 구현)
본 포스팅에서는 순차 탐색(Sequential Search)에 대해 알아봅니다. 📚 목차 1. 순차 탐색(이란? 2. 동작 과정 3. 구현(Python) 4. 시간 복잡도 1. 순차 탐색이란? 순차 탐색(Sequential Search)은 말 그대로 리스트 내 특정 데이터를 찾기 위해 앞에서부터 데이터를 차례대로 탐색하는 알고리즘입니다. 2. 동작 과정 순차 탐색의 과정은 아래와 같습니다. 풀어써서 복잡해 보이지만 맨 앞에서부터 차례대로 비교하는 단순한 방법입니다. 1️⃣ 맨 앞 데이터와 찾으려는 데이터가 같은지 탐색합니다. 2️⃣ 데이터가 서로 같지 않다면 다음 데이터와 찾으려는 데이터가 같은지 탐색합니다. 3️⃣ 같은 데이터를 찾기 전까지 2️⃣ 과정을 반복합니다. 리스트 내 데이터가 아무리 많아도 ..
 [알고리즘] 정렬 알고리즘 문제 풀이 전략!
[알고리즘] 정렬 알고리즘 문제 풀이 전략!
본 포스팅에서는 정렬 알고리즘 문제 풀이 전략을 공유합니다. 정렬 알고리즘 문제 해결 전략 알고리즘 문제 풀이에 있어서 특별히 문제에서 요구사항이 없을 경우, 단순히 정렬이 필요한 상황에서는 기본 내장 정렬 라이브러리를 활용하시는 것이 가장 좋습니다. 다만, 데이터의 범위가 한정되어 있고 더욱 빠르게 동작하도록 문제를 풀어야 한다면 계수 정렬 알고리즘을 활용하시는 것이 좋습니다. 이처럼 아래에 주어진 상황에 맞는 알고리즘 문제 풀이 전략을 정리해 보았습니다. (1) 정렬 라이브러리 활용 문제 단순히 내장 정렬 라이브러리에 대해 알고 있고 사용할 줄 아는지 묻기 위한 문제 유형입니다. 기본적으로 내장 정렬 함수 사용방법에 대해 기본적인 부분들에 대해 숙지하고 있으면 어렵지 않게 문제를 풀 수 있습니다. (..
 [알고리즘] 계수 정렬에 대해 알아보자! (+Python 구현)
[알고리즘] 계수 정렬에 대해 알아보자! (+Python 구현)
본 포스팅에서는 계수 정렬 알고리즘에 대해 알아봅니다. 📚 목차 1. 계수 정렬이란? 2. 계수 정렬의 동작 과정 3. 계수 정렬의 구현(Python) 4. 계수 정렬의 시간 복잡도 1. 계수 정렬이란? 계수 정렬은 데이터 개수가 많더라도 매우 빠르게 동작하는 정렬 알고리즘 중 하나로서 리스트가 모두 정수 형태로 표현되어 있고 가장 작은 데이터와 가장 큰 데이터의 차이가 1백만(1,000,000) 이하일 때 효과적으로 동작합니다. 이처럼 특정 조건이 부합할 때만 동작하는 이유는 계수 정렬을 활용할 때는 가장 작은 데이터부터 가장 큰 데이터까지 모든 범위의 데이터를 담을 수 있는 크기의 리스트를 선언해야 하기 때문입니다. 예를 들어, 가장 작은 데이터와 가장 큰 데이터의 차이가 1,000,000이라면 총 ..
 [알고리즘] 퀵 정렬에 대해 알아보자! (+Python 구현)
[알고리즘] 퀵 정렬에 대해 알아보자! (+Python 구현)
본 포스팅에서는 퀵 정렬(Quick sort) 알고리즘에 대해 알봅니다. 📚 목차 1. 퀵 정렬이란? 2. 퀵 정렬의 동작 과정 3. 퀵 정렬 구현(Python) 4. 퀵 정렬의 시간 복잡도 1. 퀵 정렬이란? 퀵 정렬은 피벗(pivot)이라는 기준 데이터를 설정하고 그 기준 데이터보다 큰 데이터와 작은 데이터의 위치를 변경하는 정렬 방식입니다. 퀵 정렬은 데이터 간의 비교만으로 정렬을 수행하는 비교 정렬 중 하나로서 이름에서 알 수 있듯이 정렬이 빠르다는 특징이 있습니다. 퀵 정렬의 방식은 피벗을 설정하고 데이터를 분할하는 방법에 따라 여러 가지로 구분할 수 있지만, 이번 포스팅에서는 가장 대표적인 분할 방식인 호어 분할(Hoare Partition)을 기준으로 설명드리도록 하겠습니다. 2. 퀵 정렬의..