
목록View All (350)
DATA101
 문자열처리 #백준10809 #알파벳 찾기 | 파이썬 풀이
문자열처리 #백준10809 #알파벳 찾기 | 파이썬 풀이
📚 문제 링크: https://www.acmicpc.net/problem/10809 10809번: 알파벳 찾기 각각의 알파벳에 대해서, a가 처음 등장하는 위치, b가 처음 등장하는 위치, ... z가 처음 등장하는 위치를 공백으로 구분해서 출력한다. 만약, 어떤 알파벳이 단어에 포함되어 있지 않다면 -1을 출 www.acmicpc.net 💡 접근법 입력받는 단어의 좌측부터 알파벳부터 차례로 접근하여 몇 번째 알파벳인지 확인하여 정답으로 출력할 리스트를 업데이트하면 됩니다. 저는 a부터 z까지 모든 소문자 알파벳을 문자열로 받아오기 위해 파이썬 string 라이브러리 내 ascii_lowercase 함수를 활용하였습니다. 그리고, 문자열 탐색 결과를 저장할 리스트 원소는 모두 -1로 초기화하였습니다. 입..
 문자열처리 #백준1152 #단어의 개수 | 파이썬 풀이
문자열처리 #백준1152 #단어의 개수 | 파이썬 풀이
📚 문제 링크: https://www.acmicpc.net/problem/1152 1152번: 단어의 개수 첫 줄에 영어 대소문자와 공백으로 이루어진 문자열이 주어진다. 이 문자열의 길이는 1,000,000을 넘지 않는다. 단어는 공백 한 개로 구분되며, 공백이 연속해서 나오는 경우는 없다. 또한 문자열 www.acmicpc.net 💡 접근법 파이썬의 문자열 split 함수를 통해 공백 구분자를 기준으로 문장을 단어 단위로 나눈 리스트를 만들어 준 후, 해당 리스트의 길이를 출력하면 쉽게 해결할 수 있습니다. 💻 코드 print(len(input().split())) 포스팅 내용에 오류가 있거나 조언/지적/피드백 환영입니다!😄 아래에 👇👇👇 댓글 남겨주시면 감사드리겠습니다. 그럼 오늘도 즐겁고 건강한 하..
 [Github] Pull 에러 해결하기 "Please commit your changes or stash them before you merge."
[Github] Pull 에러 해결하기 "Please commit your changes or stash them before you merge."
안녕하세요! 오늘은 아래와 같은 원격 저장소 pull 도중 마주할 수 있는 에러에 대응하는 방법을 공유합니다. error: Your local changes to the following files would be overwritten by merge: ... Please commit your changes or stash them before you merge. 🔥 에러 상황 원격저장소에서 로컬로 파일을 pull 하던 중 에러 메시지를 마주했습니다. git pull origin main 에러 메시지(그림 1)👇 From https://github.com/park-gb/algorithm-problem-solving * branch main -> FETCH_HEAD Updating 840480f..9f7b..
 [Github] "fatal: 'origin' does not appear to be a git repository" 저장소 연결 문제 해결하기!
[Github] "fatal: 'origin' does not appear to be a git repository" 저장소 연결 문제 해결하기!
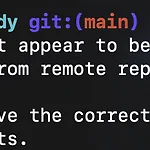
안녕하세요! 오늘은 Github 사용 중 "fatal: remote origin already exists." 에러 메시지에 대응하는 방법을 공유합니다. 🔥 에러 상황 리포지토리 여러 곳을 옮겨다니며 파일을 업데이트 하는 중이었습니다. git push -f origin main 파일을 push 하던 중 아래와 같은 에러 메시지를 접했습니다(그림 1). fatal: 'origin' does not appear to be a git repository fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists. 💡 해결방법 해결 방법은 원격 저장소..
 [Github] "fatal: remote origin already exists." 원격 저장소 연결 문제 해결하기!
[Github] "fatal: remote origin already exists." 원격 저장소 연결 문제 해결하기!
안녕하세요! 오늘은 Github 사용 중 "fatal: remote origin already exists." 에러 메시지에 대응하는 방법을 공유합니다. 🔥 에러 상황 Gitub에 새로운 리포지토리를 생성하고, 터미널에서 해당 저장소에 연결을 시도했습니다. git remote add origin https://github.com/park-gb/algorithm-practice.git 방금 만든 리포지토리임에도 이미 저장소와 연결되어 있다는 메시지가 나오네요? fatal: remote origin already exists. 연결 상태를 확인해 봤습니다. git remote -v 아래 그림 1과 같이, 연결을 시도했던 저장소가 아닌 다른 저장소에 연결되어 있는 상태였습니다. How to solve this..
 문자열처리 #백준11720 #숫자의 합 | 파이썬 풀이
문자열처리 #백준11720 #숫자의 합 | 파이썬 풀이
📚 문제 링크: https://www.acmicpc.net/problem/11720 11720번: 숫자의 합 첫째 줄에 숫자의 개수 N (1 ≤ N ≤ 100)이 주어진다. 둘째 줄에 숫자 N개가 공백없이 주어진다. www.acmicpc.net 💡 접근법 문자열은 반복문을 통해 차례로 인덱싱할 수 있다는 점에, 자릿수마다 숫자를 정수형으로 변환한 값을 차례로 합하면 쉽게 해결이 가능합니다. 💻 코드 def main(): n = int(input()) # 문자열 개수 n_total = input() # 숫자 N개 문자열로 입력 answer = 0 for number in n_total: answer+= int(number) print(answer) if __name__ == "__main__": main(..
 [Python] Binary Classfication 모델링 코드 공유(feat. Wine Quality Dataset)
[Python] Binary Classfication 모델링 코드 공유(feat. Wine Quality Dataset)
안녕하세요, 오늘은 머신러닝 알고리즘 Random Forest로 Binary Classification 모델링하는 절차와 방법을 공유하고자 합니다. 실습 데이터는 오픈소스인 Wine Quality Data Set입니다. 1. 실습코드 및 데이터셋 데이터셋과 전체 파이썬 코드는 이곳에서 받으실 수 있습니다. GitHub - park-gb/wine-data-classification: The wine data classification using machine learning algorithms The wine data classification using machine learning algorithms - GitHub - park-gb/wine-data-classification: The wine dat..
 [Python] Random Forest 알고리즘 정의, 장단점, 최적화 방법
[Python] Random Forest 알고리즘 정의, 장단점, 최적화 방법
📚목차 1. 랜덤포레스트 정의 2. 랜덤포레스트 장단점 3. 실습코드 및 데이터셋 4. 코드 설명 1. Random Forest 정의 Random Forest는 의사결정나무 모델 여러 개를 훈련시켜서 그 결과를 종합해 예측하는 앙상블 알고리즘입니다. 각 의사결정나무 모델을 훈련시킬 때 배깅(Bagging) 방식을 사용합니다. 배깅은 전체 Train dataset에서 중복을 허용해 샘플링한 Dataset으로 개별 의사결정나무 모델을 훈련하는 방식입니다. 이렇게 여러 모델을 통해 예측한 값은 평균을 취하여 최종적인 예측값을 산출합니다. 이 배깅 방식은 예측 모델의 일반화(generalization, a.k.a., 안정성) 성능을 향상하는 데 도움이 됩니다. 2. 랜덤포레스트 장단점 장점 단점 일반화 및 성능..